Lesson 9: Multiple Linear Regression
Overview
Overview
In the previous lesson, you have learned how to implement simple linear regression, in which you have one response variable and one predictor variable. In this lesson, we will expand what you have learned to multiple linear regression. Here, you will still have a single response variable, but will include multiple explanatory variables in your model.
Learning Outcomes
By the end of this lesson, you should be able to:
-
choose which variables to include in a multiple regression model
-
evaluate interactions between variables in a mutiple regression model
Lesson Roadmap
| Type | Assignment | Location |
|---|---|---|
| To Read | Lock et. al. 10.1-10.3 | Textbook |
| To Do |
Complete Homework: H11 Multiple Regression Take Quiz 9 |
Canvas |
Questions?
If you prefer to use email:
If you have any questions, please send a message through Canvas. We will check daily to respond. If your question is one that is relevant to the entire class, we may respond to the entire class rather than individually.
If you prefer to use the discussion forums:
If you have questions, please feel free to post them to the General Questions and Discussion forum in Canvas. While you are there, feel free to post your own responses if you, too, are able to help a classmate.
Introduction to Multiple Linear Regression
Introduction to Multiple Linear Regression
 Read It: Multiple Linear Regression
Read It: Multiple Linear Regression
At its core, multiple linear regression is very similar to simple linear regression. Recall the equation for a simple linear model from Lesson 8:
In this equation, we have a single explanatory variable (also known as a predictor), which is denoted with . To define a multiple linear regression model, we maintain this same basic formula, but add more explanatory variables:
Notice that we do not include multiple X values (e.g., ) to indicate the multiple explanatory variables included in the model.
Another similarity between simple linear regression and multiple linear regression are the conditions that need to be met for statistical validity. Recall from Lesson 8, the three conditions for simple linear regression are: (a) linear shape, (b) constant variance, and (c) no outliers. Multiple linear regression has the same conditions, except we test them by plotting the predicted values vs. the residuals, as shown below.
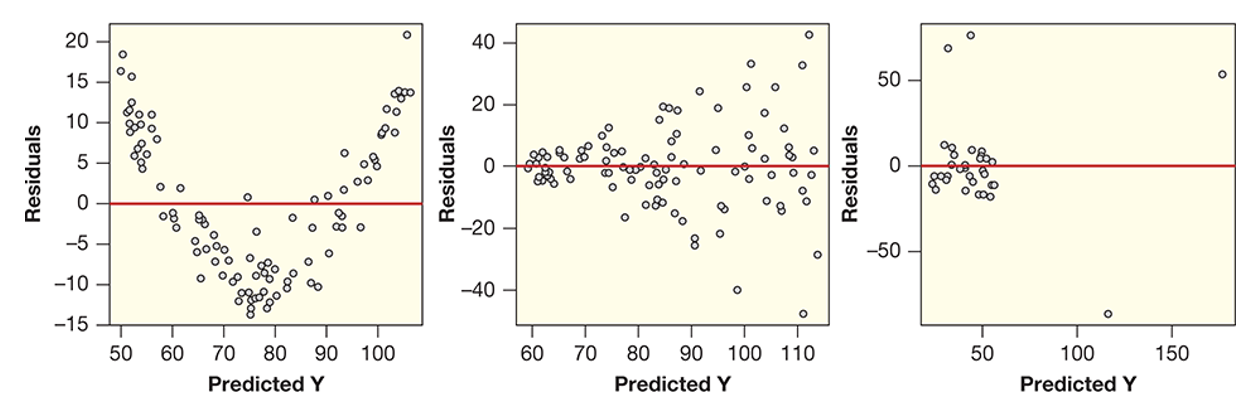
Notice, for example, the curved shape between the predicted Y values and the residuals in Figure (a), this is an indication that there is a nonlinear relationship, which breaks the conditions for multiple linear regression. Likewise, in Figure (b), there is a clear fan or wedge shape between the predicted Y values and the residuals, which breaks the constant variance condition. Finally, in Figure (c), there are clear outliers, which breaks the no outliers condition. Below, we show the ideal plot of predicted Y values vs. residuals, in which none of the conditions are broken.
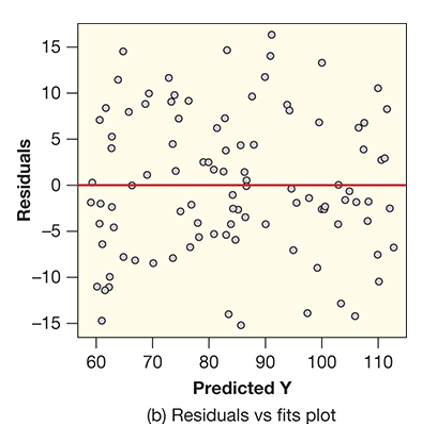
You may have noticed that all of these plots are working with the predicted Y values, rather than the actual values. This means that we can only assess the validity of our multiple linear regression model after we actually implement the model. This is a particular limitation of multiple linear regression, as it can often we a lot of work to build the model, only to find out that it doesn't meet the statistical conditions. Nonetheless, the ability to include additional explanatory variables often improves our model, so it is generally a worthwhile endeavor to spend some time perfecting the multiple linear regression model.
 Assess It: Check Your Knowledge
Assess It: Check Your Knowledge
Knowledge Check
Interpreting the Output from Multiple Linear Regression
Interpreting the Output from Multiple Linear Regression
Read It: Interpreting Output from Multiple Linear Regression
After implementing multiple linear regression in Python, the primary source of interpretation will be the output of the model summary, an example of which is shown below.

There are three key areas to focus on in this plot. The first is the F-statistic and its associated p-value. As in Lesson 8, these values can be used to determine model effectiveness using the F-statistic hypothesis test. For multiple linear regression, however, the alternative hypothesis is slightly different, as shown below.
Notice how the alternative tells us that at least one explanatory variable (predictor) is effective, rather than focusing on the model as a whole. To figure out which predictors are effective, you need to look at the lower half of the output, where the coefficients, t-statistic, and associated p-values are listed. These p-values tell you how significant a given explanatory variables, with values < 0.05 (or your chosen significance level) being significant. You can also use these p-values to test the significance of the coefficient using the hypothesis tests below, notice that they are similar to those you learned in Lesson 8 for the hypothesis test for slope.
Finally, the last piece of critical information in the model summary is the Adjusted R2 value. This is the value that you will use to determine the "goodness of fit" for any multiple linear regression models. In particular, the Adjusted R2 value accounts for model complexity, as well as the difference between the predicted and actual values. In this sense, adding explanatory variables that don't contribute to the model accuracy can actually reduce your Adjusted R2. Mathematically, the Adjusted R2 is represented below. You may notice in the above output that the Adjusted R2 and regular R2 are the same, this happens when there are no insignificant explanatory variables in your model. That being said, it is much more common to have a regular R2 that is greater than your Adjusted R2.
Assess It: Check Your Knowledge
Knowledge Check
Implementing Multiple Linear Regression in Python
Implementing Multiple Linear Regression in Python
Read It: Implementing Multiple Linear Regression in Python
In this course we will be implementing multiple linear regression in Python. In particular, we will be using the .ols command from the statsmodels.formula.api library that you learned about in Lesson 8. More information on this command canbe found in the documentation [2]. Below we will demonstrate how to implement multiple linear regression through two videos. The first will set up the data, while the second will focus on the acutal implementation.
 Watch It: Video - Data Set Up Visualization (6:50 minutes)
Watch It: Video - Data Set Up Visualization (6:50 minutes)
Watch It: Video - Multiple Linear Regression (9:21 minutes)
 Try It: DataCamp - Apply Your Coding Skills
Try It: DataCamp - Apply Your Coding Skills
Using the partial code below, implement a multiple linear regression model. Your response variable should be 'y' and the remaining variables should be used as explanatory variables.
Assess It: Check Your Knowledge
Knowledge Check
Correlation-Based Variable Selection
Correlation-Based Variable Selection
Read It: Correlation-Based Variable Selection
One way to selet the optimal variables for multiple linear regression is through a correlation analysis. By determining which explanatory variables are most highly correlated with the response, you can get a better idea of important variables, thus implement models with higher adjusted R2 values. Below, we demonstrate how to implement this process in Python.
Watch It: Video - Correlation Variable Selection (10:13 minutes)
Try It: DataCamp - Apply Your Coding Skills
Using the pre-coded variables below. Calculate and print the correlation matrix. Are any of the variables highly correlated? Which would you include in your multiple linear regression model?
Assess It: Check Your Knowledge
Knowledge Check
Interaction Effects
Interaction Effects
Read It: Interaction Effects
When developing multiple linear regression models, it is possible to account for interactions between the variables. For example, maybe variable 'x' is not a great predictor of 'y', but the combined effect of 'x' and 'z' is an important predictor. In this case, the interactions can improve the accuracy of our model. In Python, we signify interactions with an asterisk (*) or a colon (:), depending on the type of interaction. The *, for example, indicates that Python should consider both the interaction between two terms and as separate predictors, while the : tells Python that you only want to consider the interaction. Below, we demonstrate the use of these key symbols in Python.
Watch It: Video - Interaction Effects (8:43 minutes)
Try It: DataCamp - Apply Your Coding Skills
Edit the following code to implement multiple linear regression with interaction effects. Your response variable is 'y' and all other variables can be used as explanatory variables.
Assess It: Check Your Knowledge
Knowledge Check
Summary and Final Tasks
Summary
Through this lesson, you are now able to use Python to conduct multiple linear regression and interpret those results. You should also be able to select variables to include in your multiple linear regression analysis and explain why those variables were chosen. Finally, you should understand how interaction effects work in multiple linear regression and be able to implement those interactions in Python.
Assess it: Check Your Knowledge Quiz
Reminder - Complete all of the Lesson 9 tasks!
You have reached the end of Lesson 9! Double-check the to-do list on the Lesson 9 Overview page to make sure you have completed all of the activities listed there before you begin Lesson 10.