1.6 Performance and how it can be improved
1.6 Performance and how it can be improved
Now that we are back into the groove of writing arcpy code and creating script tools, we want to look at a topic that didn't play a big role in our introductory class, GEOG 485, but that is very important to programming: We want to talk about run-time performance and the related topics of parallelisation and code profiling. These will be the main topics of the next sections and this lesson in general.
We are going to address the question of how we can improve the performance and reliability of our Python code when dealing with more complicated tasks that require a larger number of operations on a greater number of datasets and/or more memory. To do this we’re going to look at both 64-bit processing and multiprocessing. We’re going to start investigating these topics using a simple raster script to process LiDAR data from Penn State’s main campus and surrounding area. In later sections, we will also look at a vector data example using different data sets for Pennsylvania.
The raster data consists of 808 tiles which are all individually zipped, 550MB zipped in total. The individual .zip files can be downloaded from PASDA directly [1].
Previously PASDA provided access via FTP but unfortunately that ability has been removed. However, we recommend you use a little Python script we put together that uses BeautifulSoup (which we'll look at more in Lesson 2) to download the files. The script will also automatically extract the individual .zip files. For this you have to do the following:
- Download and unzip the script from here [2].
- At the beginning of the main function, two folders are specified, the first one for storing the .zip files and the second for storing the extracted raster files. These are currently set to C:\temp and C:\temp\unzipped but you may not have the permissions to write to these folders. We therefore recommend that you edit these variables to have the LiDAR files downloaded and extracted to folders within your Windows user's home directory, e.g. C:\Users\<username>\Documents\489 and C:\Users\<username>\Documents\489\unzipped (assuming that the folder 489 already exist in your Documents folder). The script uses a wildcard on line 66 that tells Python to only download tile files with 227 in the file name, not all of them. This is ok for running the code examples in this lesson but if you want to do test runs with more or all the files, you can also edit this line so that it reads wildcard_pattern = "zip" (because "zip" exists in all the filenames)
- Run the script and you should see the downloaded .zip files and extracted raster files appear in the specified target folders.
Doing any GIS processing with these LiDAR files is definitely a task to be handled by scripting, and any performance benefits we can gain when we’re processing that many tiles will be worthwhile. The question you might be asking is why don’t we just join all of the tiles together and process them at once - we’d run out of memory very fast and if something goes wrong we need to start over. Processing small tiles we can do one (or a few) at a time using less memory and if one tile fails we still have all of the others and just need to restart that tile.
Below is our simple raster script which gets our list of tiles and then for every tile in the list we fill the DEM, create a flow direction and flow accumulation raster to then derive a stream raster (to determine where the water might flow), and lastly we convert the stream raster to polygon or polyline feature classes. This is a simplified version of the sort of analysis you might undertake to prepare data prior to performing a flood study. The code we are writing here will work in both Desktop and Pro as long as you have the Spatial Analyst extension installed, authorized and enabled (it is this last step that generally causes errors). I’ve restricted the processing to a subset of those tiles for testing and performance reasons using only tiles with 227 in the name but more tiles can be included by modifying the wild card list in line 19.
If you used the download script above, you already have the downloaded raster files ready. You can move them to a new folder or keep them where they are. In any case, you will need to make sure that the workspace in the script below points to the folder containing the extracted raster files (line 9). If you obtained the raster files in some other way, you may have to unzip them to a folder first.
Let’s look over the code now.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | # Setup _very_ simple timing. import time process_start_time = time.time() import arcpy from arcpy.sa import *arcpy.env.overwriteOutput = Truearcpy.env.workspace = r'C:\489\PSU_LiDAR'## If our rasters aren't in our filter list then drop them from our list. def filter_list(fileList,filterList): return[i for i in fileList if any(j in i for j in filterList)] # Ordinarily we would want all of the rasters I'm filtering by a small set for testing & efficiency # I did this by manually looking up the tile index for the LiDAR and determining an area of interest # tiles ending in 227, 228, 230, 231, 232, 233, 235, 236 wildCardList = set(['227']) ##,'228','230','231','232','233','235','236']) # Get a list of rasters in my folder rasters = arcpy.ListRasters("*") new_rasters = filter_list(rasters,wildCardList) # for all of our rasters for raster in new_rasters: raster_start_time = time.time() # Now that we have our list of rasters ## Note also for performance we're not saving any of the intermediate rasters - they will exist only in memory ## Fill the DEM to remove any sinks try: FilledRaster = Fill(raster) ## Calculate the Flow Direction (how water runs across the surface) FlowDirRaster = FlowDirection(FilledRaster) ## Calculate the Flow Accumulation (where the water accumulates in the surface) FlowAccRaster = FlowAccumulation(FlowDirRaster) ## Convert the Flow Accumulation to a Stream Network ## We're setting an arbitray threshold of 100 cells flowing into another cell to set it as part of our stream Streams = Con(FlowAccRaster,1,"","Value > 100") ## Convert the Raster Stream network to a feature class output_Polyline = raster.replace(".img",".shp") arcpy.CheckOutExtension("Spatial") arcpy.sa.StreamToFeature(Streams,FlowDirRaster,output_Polyline) arcpy.CheckInExtension("Spatial") except: print ("Errors occured") print (arcpy.GetMessages()) arcpy.AddMessage ("Errors occurred") arcpy.AddMessage(arcpy.GetMessages()) # Output how long the whole process took. arcpy.AddMessage("--- %s seconds ---" % (time.time() - process_start_time)) print ("--- %s seconds ---" % (time.time() - process_start_time)) |
We have set up some very simple timing functionality in this script using the time() function defined in the module time of the Python standard library. The function gives you the current time and, by calling it at the beginning and end of the program and then taking the difference in the very last line of the script, we get an idea of the runtime of the script.
Later in the lesson, we will go into more detail about properly profiling code where we will examine the performance of a whole program as well as individual instructions. For now, we just want an estimate of the execution time. Of course, it’s not going to be very precise as it will depend on what else you’re doing on your PC at the same time and we would need to run a number of iterations to remove any inconsistencies (such as the delay when arcpy loads for the first time etc.). On my PC that code runs in around 40 seconds. Your results will vary depending on many factors related to the performance of your PC (we'll review some of them in the Speed Limiters section) but you should test out the code to get an idea of the baseline performance of the algorithm on your PC.
In lines 12 and 13, we have a simple function to filter our list of rasters to just those we want to work with (centered on the PSU campus). This function might look a little different to what you have seen before - that's because we're using list comprehension which we'll examine in more detail in Lesson 2 [3]. So don't worry about understanding how exactly this works at the moment. It basically says to return a list with only those file names from the original list that contain one of the numbers in the wild card list.
We set up some environment variables, our wildcard list (used by our function for filtering) at line 19 - where you will notice I have commented out some of the list for speed during testing, and then we get our list of rasters, filter it and for those rasters left and we iterate through them with the central for-loop in line 25 performing our spatial analysis tasks mentioned earlier. There is some basic error checking wrapped around the tasks (which is also reporting running times if anything goes wrong) and then lastly there is a message and print function with the total time. I’ve included both print and AddMessage just in case you wanted to test the code as a script tool in ArcGIS.
Feel free to run the script now and see what total computation time you get from the print statement in the last line of the code. We‘re going to demonstrate some very simple performance evaluation of the different versions of ArcGIS (32 bit Desktop, 64 bit Desktop, Pro and arcpy Multiprocessing) using this code. Before we do that though it is important to understand the differences between each of them. You do not have to run this testing yourself; we’re mainly providing it as some background. You are welcome to experiment with it, but please do not do that to the detriment of your project.
Once we’ve examined the theory of 64-bit processing and parallelisation and worked through a simple example using the Hi-ho Cherry-O game from GEOG 485, we’ll come back to the raster example above and convert it to running in parallel using the Python multiprocessing package instead of sequentially and we will further look at an example of multiprocessing using vector data.
1.6.1 32-bit vs. 64-bit processing
1.6.1 32-bit vs. 64-bit processing
32-bit software or hardware can only directly represent and operate with numbers up to 2^32 and, hence, can only address up to a maximum of 4GB of memory (that is 2^32 = 4294967296 bytes). If the file system of your operating system is limited to 32-bit integers as well, this also means you cannot have any single file larger than 4GB either in memory or on disk (you can still page or chain larger files together though).
64-bit architectures don’t have this limit. Instead you can access up to 16 terabytes of memory and this is actually only the limit of current chip architectures which "only" use 44 bits which will change over time as software and hardware architectures evolve. Technically with a 64-bit architecture you could access 16 Exabytes of memory (2^64) and while not wanting to paraphrase Bill Gates, that is probably more than we’ll need for the foreseeable future.
There most likely won't be any innate performance benefits to be gained by moving from 32-bit and 64-bit unless you need that extra memory. While in principle, you can move larger amounts of data per time between memory and CPU with 64-bit, this typically doesn't result in significantly improved execution times because of caching and other optimization techniques used by modern CPUs. However if we start using programming models where we run many tasks at once, you might want more than 4GB allocated to those processes. For example if you had 8 tasks that all needed 500MB of RAM each – that’s very close to the 4GB limit in total (500MB * 8 = 4000MB). If you had a machine with more processors (e.g. 64) you would very easily hit the 32-bit 4GB limit as you would only be able to allocate 62.5MB of RAM per processor from your code.
Even with hardware architectures and operating systems mainly being 64-bit these days, a lot of software still is only available as 32-bit versions. 64-bit operating systems are designed to be backwards compatible with 32-bit applications, and if there is no real expected benefit for a particular software, the developer of the software may just as well decide to stick with 32-bit and avoid the efforts and costs that it would take to make the change to 64-bit or even support multiple versions of the software. ArcGIS Desktop is an example of a software that is only available as 32-bit and this is (most likely) not going to change anymore since ArcGIS Pro, which is 64-bit, fills that role. However, Esri also provides a 64-bit geoprocessing extension for ArcGIS Desktop which will be further described in the next section. However, this section is considered optional. You may read through it and learn how it can be set up and about what performance gain can be achieved using it or you may skip most of it and just have a look at the table with the computation time comparison at the very end of the section. But we strongly recommend that you do not try to install 64-bit geoprocessing and perform the steps yourself before you have worked through the rest of lesson and the homework assignment.
1.6.2 Optional complementary materials: 64-bit background geoprocessing in ArcGIS Desktop
1.6.2 Optional complementary materials: 64-bit background geoprocessing in ArcGIS Desktop
This section is provided for interest only - as it only applies to ArcGIS Desktop - not Pro (which is natively 64 bit). It is recommended that you only read/skim through the section and check out the computation time comparison at the end without performing the described steps yourself and then loop back to it at the end of the lesson if you have free time and are interested in exploring 64-bit Background Geoprocessing in ArcGIS Desktop.
A number of versions ago (since Server 10.1), Esri added support for 64-bit arcpy. Esri also introduced 64-bit geoprocessing using the 64-bit Background Geoprocessing patch which was part of 10.1 Service Pack 1 as an option in ArcGIS Desktop (Pro is entirely 64-bit) to work around these memory issues for large geoprocessing tasks. Not all tools support 64-bit geoprocessing within Desktop and there are some tricks to getting it installed so you can access it in Desktop. There is also a 64-bit arcpy geoprocessing library so you can run your code (any code) from the command line. Background Geoprocessing (64-bit) is still available as a separate installation on top of ArcGIS (see this ArcMap/Background Geoprocessing (64-bit) page [4]) and we’ve provided a link for students to obtain it within Canvas. You'll find this link on the "64-bit Geoprocessing downloads for ArcGIS (optional)" page under Lesson 1 in Canvas.
As Esri hint in their documentation, 64-bit processing within ArcGIS Desktop requires that the tool run in the background. This is because it is running using a separate set of tools which are detached from the Desktop application (which is 32-bit). Personally, I rarely use Background Geoprocessing but I do make use of the 64-bit version of Python that it installs to run a lot of my scripts in 64-bit mode from the command line.
If you’ve typically run your code in the past from within an IDE (such as PythonWin, IDLE or spyder) or from within ArcGIS you might not be aware that you can also run that code from the command line by calling Python directly.
For ArcGIS Desktop you can start a regular command prompt and, using the standard Windows commands, change to that path where your Python script is located. Usually when you open a command window, it will start in your home folder (e.g. c:\users\yourname). We could dedicate an entire class to operating system commands but Microsoft has a good resource at this Windows Commands page [5] for those who are interested.
We just need a couple of the commands listed there :
- cd : change directory. We use this to move around our folders. Full help at this Commands/cd page [6].
- dir : list the files and folders in my directory. Full help at this Commands/dir page [7].
We’ll change the directory to where our code [8] from section 1.6 is (e.g. mine is c:\wcgis\geog489\lesson1) and see how to run the script using the command line versions of 32-bit and 64-bit Python.
cd c:\wcgis\geog489\lesson1
If you downloaded and installed the 64-bit Background Geoprocessing from above you will have both 32-bit and 64-bit Python installed. We’ll use the 32-bit Python first which should be located at c:\python27\arcgis10.6\python.exe (substitute 10.6 by whichever version of ArcGIS you have installed).
There’s a neat little feature built into the command line where you can use the TAB key to autocomplete paths so you could start typing c:\python27\a and then hit TAB and you should see the path cycling through the various ArcGIS folders.
We’ll run our code using:
C:\python27\ArcGIS10.6\python.exe myScriptName.py
Where myScriptName.py is whatever you saved the code from section 1.6 as. You will now see the code run in the command window and pop up all of the same messages you would have seen if you had run it from an IDE (but not the AddMessages messages as they are only interpreted by ArcGIS).
To run the code against the 64-bit version of Python the command is almost identical except that you’ll use the x64 version of Python that has been installed by Background Geoprocessing. In my case that means the command is:
C:\python27\ArcGISx6410.5\python.exe myScriptName.py
Once your script finishes you’ll have a few time stamp values. Running that code from Section 1.6 through the 32-bit and 64-bit versions a few times we have some sample results below. The first runs of each are understandably slower as arcpy is imported for the first time. You have probably witnessed this behavior yourself as your code takes longer the very first time it runs.
| 32-bit Desktop | 64-bit Desktop | 64-bit Pro |
|---|---|---|
| 149 seconds | 107 seconds | 109 seconds |
| 119 seconds | 73 seconds | 144 seconds |
| 91 seconds | 90 seconds | 111 seconds |
| 85 seconds | 73 seconds | |
| 93 seconds | 75 seconds |
We can see a couple of things with these results – they are a little inconsistent depending on what else my PC was doing at the time the code was running and, if you are looking at individual executions of the code, it is difficult to see which pieces of the code are slower or faster from time to time. This is the problem that we will solve later in the lesson when we look at profiling code where we examine how long each line of code takes to run.
1.6.3 Parallel processing
1.6.3 Parallel processing
You have probably noticed if you have a relatively modern PC (anything from the last several years) that when you open Windows Task Manager (from the bottom of the list when you press CTRL-ALT-DEL) and you click the Performance tab and right click on the CPU graph and choose Change Graph to -> Logical Processors you have a number of processors (or cores) within your PC. These are actually “logical processors“ within your main processor but they function as though they were individual processors – and we’ll just refer to them as processors here for simplicity.

Now because we have multiple processors, we can run multiple tasks in parallel at the same time instead of one at a time. There are two ways that we can run tasks at the same time – multithreaded and multiprocessing. We’ll look at the differences in each in the following but it’s important to know that arcpy doesn’t support multithreading but it does support multiprocessing. In addition, there is a third form of parallelisation called distributed computing, which involves distributing the task over multiple computers, that we will also briefly talk about.
1.6.3.1 Multithreading
1.6.3.1 Multithreading
Multithreading is based on the notion of "threads" for a number of tasks that are executed within the same memory space. The advantage of this is that because the memory is shared between the threads they can share information. This results in a much lower memory overhead because information doesn’t need to be duplicated between threads. The basic logic is that a single thread starts off a task and then multiple threads are spawned to undertake sub-tasks. At the conclusion of those sub-tasks all of the results are joined back together again. Those threads might run across multiple processors or all on the same one depending on how the operating system (e.g. Windows) chooses to prioritize the resources of your computer. In the example of the PC above which has 4 processors, a single-threaded program would only run on one processor while a multi-threaded program would run across all of them (or as many as necessary).
1.6.3.2 Multiprocessing
1.6.3.2 Multiprocessing
Multiprocessing achieves broadly the same goal as multi-threading which is to split the workload across all of the available processors in a PC. The difference is that multiprocessing tasks cannot communicate directly with each other as they each receive their own allocation of memory. That means there is a performance penalty as information that the processes need must be stored in each one. In the case of Python a new copy of python.exe (referred to as an instance) is created for each process that you launch with multiprocessing. The tasks to run in multiprocessing are usually organized into a pool of workers which is given a list of the tasks to be completed. The multiprocessing library will assign each task to a worker (which is usually a processor on your PC) and then once a worker completes a task the next one from the list will be assigned to that worker. That process is repeated across all of the workers so that as each finishes a task a new one will be assigned to them until there are no more tasks left to complete.
You might have heard of the MapReduce framework which underpins the Hadoop parallel processing approach. The use of the term map might be confusing to us as GIS folks as it has nothing to do with our normal concept of maps for displaying geographical information. Instead in this instance map means to take a function (as in a programming function) and apply it once to every item in a list (e.g. our list of rasters from the earlier example).
The reduce part of the name is similar as we apply a function to a list and combine the results of our function into a single result (e.g. a list from 1 – 10,000 which is our number of Hi-ho Cherry-O games and we want the number of turns for each game).
The two elements map and reduce work harmoniously to solve our parallel problems. The map part takes our one large task (which we have broken down into a number of smaller tasks and put into a list) and applies whatever function we give it to the list (one item in the list at a time) on each processor (which is called a worker). Once we have a result, that result is collected by the reduce part from each of the workers and brought back to the calling function. There is a more technical explanation in the Python documentation [9].
Multiprocessing in Python
At around the same time that Esri introduced 64-bit processing, they also introduced multiprocessing to some of the tools within ArcGIS Desktop (mostly raster based tools in the first iteration) and also added multiprocessor support to the arcpy library.
Multiprocessing has been available in Python for some time and it’s a reasonably complicated concept so we will do our best to simplify it here. We’ll also provide a list of resources at the end of this section for you to continue exploring if you are interested. The multiprocessing package of Python is part of the standard library and has been available since around Python 2.6. The multiprocessing library is required if you want to implement multiprocessing and we import it into our code just like any other package using:
1 | import multiprocessing |
Using multiprocessing isn’t as simple as switching from 32-bit to 64-bit as we did above. It does require some careful thought about which processes we can run in parallel and which need to run sequentially. There are also issues about file sharing and file locking, performance penalties where sometimes multiprocessing is slower due to the time taken to setup and remove the multiprocessing pool, and some tasks that do not support multiprocessing. We’ll cover all of these issues in the following sections and then we’ll convert our simple, sequential raster processing example into a multiprocessing one to demonstrate all of these concepts.
1.6.3.3 Distributed processing
1.6.3.3 Distributed processing
Distributed processing is a type of parallel processing that instead of (just) using each processor in a single machine will use all of the processors across multiple machines. Of course, this requires that you have multiple machines to run your code on but with the rise of cloud computing architectures from providers such as Amazon, Google, and Microsoft this is getting more widespread and more affordable. We won’t cover the specifics of how to implement distributed processing in this class but we have provided a few links if you want to explore the theory in more detail.
In a nutshell what we are doing with distributed processing is taking our idea of multiprocessing on a single machine and instead of using the 4 or however many processors we might have available, we're accessing a number of machines over the internet and utilizing the processors in all of them. Hadoop [10]is one method of achieving this and others include Amazon's Elastic Map Reduce [11], MongoDB [12]and Cassandra [13]. GEOG 865 [14] has cloud computing as its main topic, so if you are interested in this, you may want to check it out.
1.6.4 Speed limiters
1.6.4 Speed limiters
With all of these approaches to speeding up our code, what are the elements which will cause bottlenecks and slow us down?
Well, there are a few – these include the time to set up each of the processes for multiprocessing. Remember earlier we mentioned that because each process doesn’t share memory it needs a copy of the data to use. This will need to be copied to a memory location. Also as each process runs its own Python.exe instance, it needs to be launched and arcpy needs to be imported for each instance (although fortunately, multiprocessing takes care of this for us). Still, all of that takes time to start so our code won’t appear to do much at first while it is doing this housekeeping - and if we're not starting a lot of processes then we won't see enough of a speed up in processing to make up for those start-up time costs.
Other things that can slow us down are the speed of our RAM. Access times for RAM used to be measured in nanoseconds but now are measured in megahertz (MHz). The method of calculating the speed isn’t especially important but if you’re moving large files around in RAM or performing calculations that require getting a number out of RAM, adding, subtracting, multiplying, etc. and then putting the result into another location in RAM and you’re doing that millions of times very, very small delays will quickly add up to seconds or minutes. Another speedbump is running out of RAM. While we can allocate more than 4GB per process using 64-bit programming, if we don’t have enough RAM to complete all of the tasks that we might launch then our operating system will start swapping between RAM (which is fast) and our hard disk (which isn’t – even if it’s one of the solid state types – SSDs).
Speaking of hard disks, it’s very likely that we’re loading and saving data to them and as our disks are slower than our RAM and our processors, that is going to cause a delay. The less we need to load and save data the better, so good multiprocessing practice is to keep as much data as possible in RAM (see the caveat above about running out of RAM). The speed of disks is governed by a couple of factors; the speed that the motor spins (unless it is an SSD), seek time and the amount of cache that the disk has. Here is how these elements all work together to speed up (or slow down) your code. The hard disk receives a request for data from the operating system, which it then goes looking for. This is the seek time referring to how long it takes the disk to position the read head over the segment of disk the data is located on, which is a function of motor speed as well. Then once the file is found, it needs to be loaded into memory – cache - and then this is sent through to the process that needed the data. When data is written back to your disk, the reverse process takes place. The cache is filled (as memory is faster than disks ) and then the cache is written to the disk. If the file is larger than the cache, the cache gets topped up as it starts to empty until the file is written. A slow spinning hard disk motor or a small amount of cache can both slow down this process.
It’s also possible that we’re loading data from across a network connection (e.g. from a database or remotely stored files) and that will also be slow due to network latency – the time it takes to get to and from the other device on the network with the request and the result.
We can also be slowed down by inefficient code, for example, using too many loops or an inefficient if / else / elif statement that we evaluate too many times or using a mathematical function that is slower than its alternatives. We'll examine these sorts of coding bottlenecks - or at least how to identify them when we look at code profiling later in the lesson.
1.6.5 First steps with Multiprocessing
1.6.5 First steps with Multiprocessing
From the brief description in the previous section, you might have realized that there are generally two broad types of tasks – those that are input/output (I/O) heavy which require a lot of data to be read, written or otherwise moved around; and those that are CPU (or processor) heavy that require a lot of calculations to be done. Because getting data is the slowest part of our operation, I/O heavy tasks do not demonstrate the same improvement in performance from multiprocessing as CPU heavy tasks. When there is more CPU based tasks to do, the benefit is seen when splitting that workload among a range of processors so that they can share the load.
The other thing that can slow us down is the output to the console or screen – although this isn’t really an issue in multiprocessing because printing to our output window can get messy. Think about two print statements executing at exactly the same time – you’re likely to get the content of both intermingled, leading to a very difficult to understand message or illogical order of messages. Even so, updating the screen with print statements comes with a cost.
To demonstrate this, try this sample piece of code that sums the numbers from 0-10000.
1 2 3 4 5 6 7 8 9 10 11 | # Setup _very_ simple timing.import timestart_time = time.time()sum = 0for i in range(0,10000): sum += i print(sum)# Output how long the process took.print (f"--- {time.time() - start_time}s seconds ---") |
If I run it with the print function in the loop the code takes 0.046 seconds to run on my PC.
4278 4371 4465 4560 4656 4753 4851 4950 --- 0.04600026321411133 seconds ---
If I comment the print(sum) function out, the code runs in 0.0009 seconds.
--- 0.0009996891021728516 seconds ---
In Penn State's GEOG 485 course, we simulated 10,000 runs of the children's game Cherry-O to determine the average number of turns it takes. If we printed out the results, the code took a minute or more to run. If we skipped all but the final print statement the code ran in less than a second. We’ll revisit that Cherry-O example as we experiment with moving code from the single processor paradigm to multiprocessor. We’ll start with it as a simple, example and then move on to two GIS themed examples – one raster (using our raster calculation example from before) and one vector.
If you did not take GEOG 485, you may want to have a quick look at the Chery-O description here [15].
The following is the original Cherry-O code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | # Simulates 10K game of Hi Ho! Cherry-O# Setup _very_ simple timing.import timestart_time = time.time()import randomspinnerChoices = [-1, -2, -3, -4, 2, 2, 10]turns = 0totalTurns = 0cherriesOnTree = 10games = 0while games < 10001: # Take a turn as long as you have more than 0 cherries cherriesOnTree = 10 turns = 0 while cherriesOnTree > 0: # Spin the spinner spinIndex = random.randrange(0, 7) spinResult = spinnerChoices[spinIndex] # Print the spin result # print ("You spun " + str(spinResult) + ".") # Add or remove cherries based on the result cherriesOnTree += spinResult # Make sure the number of cherries is between 0 and 10 if cherriesOnTree > 10: cherriesOnTree = 10 elif cherriesOnTree < 0: cherriesOnTree = 0 # Print the number of cherries on the tree # print ("You have " + str(cherriesOnTree) + " cherries on your tree.") turns += 1 # Print the number of turns it took to win the game # print ("It took you " + str(turns) + " turns to win the game.") games += 1 totalTurns += turnsprint("totalTurns " + str(float(totalTurns) / games))# lastline = raw_input(">")# Output how long the process took.print("--- %s seconds ---" % (time.time() - start_time)) |
We've added in our very simple timing from earlier and this example runs for me in about .33 seconds (without the intermediate print functions). That is reasonably fast and you might think we won't see a significant improvement from modifying the code to use multiprocessor mode but let's experiment.
The Cherry-O task is a good example of a CPU bound task. We’re limited only by the calculation speed of our random numbers, as there is no I/O being performed. It is also a parallel task, as none of the 10,000 runs of the game are dependent on each other. All we need to know is the average number of turns; there is no need to share any other information.
Our logic here could be to have a function Cherry_O(...) which plays the game and returns to our calling function the number of turns. We can add that value returned to a variable in the calling function and when we’re done divide by the number of games (e.g. 10,000) and we’ll have our average.
1.6.5.1 Converting from sequential to multiprocessing
1.6.5.1 Converting from sequential to multiprocessing
So with that in mind, let us examine how we can convert a simple program like Cherry-O from sequential to multiprocessing.
There are a couple of basic steps we need to add to our code in order to support multiprocessing. The first is that our code needs to import multiprocessing which is a Python library which as you will have guessed from the name enables multiprocessing support. We’ll add that as the first line of our code.
The second thing our code needs to have is a __main__ method defined. We’ll add that into our code at the very bottom with:
1 2 | if __name__ == '__main__': mp_handler() |
With this, we make sure that the code in the body of the if-statement is only executed for the main process we start by running our script file in Python, not the subprocesses we will create when using multiprocessing, which also are loading this file. Otherwise, this would result in an infinite creation of subprocesses, subsubprocesses, and so on. Next, we need to have that mp_handler() function we are calling defined. This is the function that will set up our pool of processors and also assign (map) each of our tasks onto a worker (usually a processor) in that pool.
Our mp_handler() function is very simple. It has two main lines of code based on the multiprocessing module:
The first instantiates a pool with a number of workers (usually our number of processors or a number slightly less than our number of processors). There’s a function to determine how many processors we have, multiprocessing.cpu_count(), so that our code can take full advantage of whichever machine it is running on. That first line is:
1 2 | with multiprocessing.Pool(multiprocessing.cpu_count()) as myPool: ... # code for setting up the pool of jobs |
You have probably already seen this notation from working with arcpy cursors. This with ... as ... statement creates an object of the Pool class defined in the multiprocessing module and assigns it to variable myPool. The parameter given to it is the number of processors on my machine (which is the value that multiprocessing.cpu_count() is returning), so here we are making sure that all processor cores will be used. All code that uses the variable myPool (e.g., for setting up the pool of multiprocessing jobs) now needs to be indented relative to the "with" and the construct makes sure that everything is cleaned up afterwards. The same could be achieved with the following lines of code:
1 2 3 4 | myPool = multiprocessing.Pool(multiprocessing.cpu_count())... # code for setting up the pool of jobsmyPool.close()myPool.join() |
Here the Pool variable is created without the with ... as ... statement. As a result, the statements in the last two lines are needed for telling Python that we are done adding jobs to the pool and for cleaning up all sub-processes when we are done to free up resources. We prefer to use the version using the with ... as ... construct in this course.
The next line that we need in our code after the with ... as ... line is for adding tasks (also called jobs) to that pool:
1 | res = myPool.map(cherryO, range(10000)) |
What we have here is the name of another function, cherryO(), which is going to be doing the work of running a single game and returning the number of turns as the result. The second parameter given to map() contains the parameters that should be given to the calls of thecherryO() function as a simple list. So this is how we are passing data to process to the worker function in a multiprocessing application. In this case, the worker function cherryO() does not really need any input data to work with. What we are providing is simply the number of the game this call of the function is for, so we use the range from 0-9,999 for this. That means we will have to introduce a parameter into the definiton of the cherryO() function for playing a single game. While the function will not make any use of this parameter, the number of elements in the list (10000 in this case) will determine how many timescherryO() will be run in our multiprocessing pool and, hence, how many games will be played to determine the average number of turns. In the final version, we will replace the hard-coded number by a variable called numGames. Later in this part of the lesson, we will show you how you can use a different function called starmap(...) instead of map(...) that works for worker functions that do take more than one argument so that we can pass different parameters to it.
Python will now run the pool of calls of the cherryO() worker function by distributing them over the number of cores that we provided when creating the Pool object. The returned results, so the number of turns for each game played, will be collected in a single list and we store this list in variable res. We’ll average those turns per game to get an average using the Python library statistics and the function mean().
To prepare for the multiprocessing version, we’ll take our Cherry-O code from before and make a couple of small changes. We’ll define function cherryO() around this code (taking the game number as parameter as explained above) and we’ll remove the while loop that currently executes the code 10,000 times (our map range above will take care of that) and we’ll therefore need to “dedent“ the code.
Here’s what our revised function will look like :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | def cherryO(game): spinnerChoices = [-1, -2, -3, -4, 2, 2, 10] turns = 0 cherriesOnTree = 10 # Take a turn as long as you have more than 0 cherries while cherriesOnTree > 0: # Spin the spinner spinIndex = random.randrange(0, 7) spinResult = spinnerChoices[spinIndex] # Print the spin result #print ("You spun " + str(spinResult) + ".") # Add or remove cherries based on the result cherriesOnTree += spinResult # Make sure the number of cherries is between 0 and 10 if cherriesOnTree > 10: cherriesOnTree = 10 elif cherriesOnTree < 0: cherriesOnTree = 0 # Print the number of cherries on the tree #print ("You have " + str(cherriesOnTree) + " cherries on your tree.") turns += 1 # return the number of turns it took to win the game return(turns) |
1.6.5.2 Putting it all together
Now lets put it all together. We’ve made a couple of other changes to our code to define a variable at the very top called numGames = 10000 to define the size of our range.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | # Simulates 10K game of Hi Ho! Cherry-O # Setup _very_ simple timing. import time start_time = time.time() import multiprocessing from statistics import mean import random numGames = 10000def cherryO(game): spinnerChoices = [-1, -2, -3, -4, 2, 2, 10] turns = 0 cherriesOnTree = 10 # Take a turn as long as you have more than 0 cherries while cherriesOnTree > 0: # Spin the spinner spinIndex = random.randrange(0, 7) spinResult = spinnerChoices[spinIndex] # Print the spin result #print ("You spun " + str(spinResult) + ".") # Add or remove cherries based on the result cherriesOnTree += spinResult # Make sure the number of cherries is between 0 and 10 if cherriesOnTree > 10: cherriesOnTree = 10 elif cherriesOnTree < 0: cherriesOnTree = 0 # Print the number of cherries on the tree #print ("You have " + str(cherriesOnTree) + " cherries on your tree.") turns += 1 # return the number of turns it took to win the game return(turns) def mp_handler(): with multiprocessing.Pool(multiprocessing.cpu_count()) as myPool: ## The Map function part of the MapReduce is on the right of the = and the Reduce part on the left where we are aggregating the results to a list. turns = myPool.map(cherryO,range(numGames)) # Uncomment this line to print out the list of total turns (but note this will slow down your code's execution) #print(turns) # Use the statistics library function mean() to calculate the mean of turns print(mean(turns)) if __name__ == '__main__': mp_handler() # Output how long the process took. print ("--- %s seconds ---" % (time.time() - start_time)) |
You will also see that we have the list of results returned on the left side of the = before our map function (line 40). We’re taking all of the returned results and putting them into a list called turns (feel free to add a print or type statement here to check that it's a list). Once all of the workers have finished playing the games, we will use the Python library statistics function mean, which we imported at the very top of our code (right after multiprocessing) to calculate the mean of our list in variable turns. The call to mean() will act as our reduce as it takes our list and returns the single value that we're really interested in.
When you have finished writing the code in spyder, you can run it. However, it is important to know that there are some well-documented problems with running multiprocessing code directly in spyder. You may only experience these issues with the more complicated arcpy based examples in Section 1.6.6 but we recommend that you run all multiprocessing examples from the command line rather than inside spyder.
The Windows command line and its commands have already been explained in Section 1.6.2 but since this was an optional section, we are repeating the explanation here: Use the shortcut called "Python command prompt" that can be found within the ArcGIS program group on the start menu. This will open a command window running within the Pro conda environment indicating that this is Python 3 (py3). You actually may have several shortcuts with rather similar sounding names, e.g. if you have both ArcGIS Pro and ArcGIS Desktop installed, and it is important that you pick the right one from ArcGIS Pro that mentions Python 3. The prompt will tell you that you are in the folder C:\Users\<username>\AppData\Local\ESRI\conda\envs\arcgispro-py3-clone\ or C:\Program Files\ArcGIS\Pro\bin\Python\envs\arcgispro-py3\ depending on your version of ArcGIS Pro.
We could dedicate an entire class to operating system commands that you can use in the command window but Microsoft has a good resource at this Windows Commands page [5] for those who are interested.
We just need a couple of the commands listed there :
- cd : change directory. We use this to move around our folders. Full help at this Commands/cd page [6].
- dir : list the files and folders in my directory. Full help at this Commands/dir page [7].
We’ll change the directory to where we saved the code from above (e.g. mine is in c:\489\lesson1) with the following command:
cd c:\489\lesson1
Before you run the code for the first time, we suggest you change the number of games to a much smaller number (e.g. 5 or 10) just to check everything is working fine so you don’t spawn 10,000 Python instances that you need to kill off. In the event that something does go horribly wrong with your multiprocessing code, see the information about the Windows taskkill command below. To now run the Cherry-O script (which we saved under the name cherry-o.py) in the command window, we use the command:
python cherry-o.py
You should now get the output from the different print statements, in particular the average number of turns and the time it took to run the script. If everything went ok, set the number of games back to 10000 and run the script again.
It is useful to know that there is a Windows command that can kill off all of your Python processes quickly and easily. Imagine having to open Task Manager and manually kill them off, answer a prompt and then move to the next one! The easiest way to access the command is by pressing your Windows key, typing taskkill /im python.exe and hitting Enter which will kill off every task called python.exe. It’s important to only use this when absolutely necessary as it will usually also stop your IDE from running and any other Python processes that are legitimately running in the background. The full help for taskkill is at the Microsoft Windows IT Pro Center taskkill page [16].
Look closely at the images below, which show a four processor PC running the sequential and multiprocessing versions of the Cherry-O code. In the sequential version, you’ll see that the CPU usage is relatively low (around 50%) and there are two instances of Python running (one for the code and (at least) one for spyder).
In the multiprocessing version, the code was run from the command line instead (which is why it’s sitting within a Windows Command Processor task) and you can see the CPU usage is pegged at 100% as all of the processors are working as hard as they can and there are five instances of Python running.
This might seem odd as there are only four processors, so what is that extra instance doing? Four of the Python instances, the ones all working hard, are the workers, the fifth one that isn’t working hard is the master process which launched the workers – it is waiting for the results to come back from the workers. There isn’t another Python instance for spyder because I ran the code from the command prompt – therefore spyder wasn’t running. We'll cover running code from the command prompt in the Profiling [17]section.




On this four processor PC, this code runs in about 1 second and returns an answer of between 15 and 16. That is about three times slower than my sequential version which ran in 1/3 of a second. If instead I play 1M games instead of 10K games, the parallel version takes 20 seconds on average and my sequential version takes on average 52 seconds. If I run the game 100M times, the parallel version takes around 1,600 seconds (26 minutes) while the sequential version takes 2,646 seconds (44 minutes). The more games I play, the better the performance of the parallel version. Those results aren’t as fast as you might expect with 4 processors in the multiprocessor version but it is still around half the time taken. When we look at profiling our code a bit later in this lesson, we’ll examine why this code isn’t running 4x faster.
When moving the code to a much more powerful PC with 32 processors, there is a much more significant performance improvement. The parallel version plays 100M games in 273 seconds (< 5 minutes) while the sequential version takes 3136 seconds (52 minutes) which is about 11 times slower. Below you can see what the task manager looks like for the 32 core PC in sequential and multiprocessing mode. In sequential mode, only one of the processors is working hard – in the middle of the third row – while the others are either idle or doing the occasional, unrelated background task. It is a different story for the multiprocessor mode where the cores are all running at 100%. The spike you can see from 0 is when the code was started.


Let's examine some of the reasons for these speed differences. The 4-processor PC’s CPU runs at 3GHz while the 32-processor PC runs at 2.4GHz; the extra cycles that the 4-processor CPU can perform per second make it a little quicker at math. The reason the multiprocessor code runs much faster on the 32-processor PC than the 4-processor PC is straightforward enough –- there are 8 times as many processors (although it isn’t 8 times faster – but it is close at 6.4x (32 min / 5 min)). So while each individual processor is a little slower on the larger PC, because there are so many more, it catches up (but not quite to 8x faster due to each processor being a little slower).
Memory quantity isn’t really an issue here as the numbers being calculated are very small but if we were doing bigger operations, the 4-processor PC with just 8GB of RAM would be slower than the 32-processor PC with 128GB. The memory in the 32-processor PC is also faster at 2.13 GHz versus 1.6GHz in the 4-processor PC.
So the takeaway message here is if you have a lot of tasks that are largely the same but independent of each other, you can save a significant amount of time utilizing all of the resources within your PC with the help of multiprocessing. The more powerful the PC, the more time that can potentially be saved. However, the caveat is that as already noted multiprocessing is generally only faster for CPU-bound processes, not I/O-bound ones.
1.6.5.3 Multiprocessing Variants
Python includes several different methods for executing processes in parallel. Each method behaves a little differently, and it is important to know some of these differences in order to get the most performance gain out of multiprocessing, and to avoid inadvertently introducing logical errors into your code. The table below provides some comparisons of the available methods to help summarize their abilities. Some things you should think about while choosing an appropriate method for your task is if the method is blocking, accepts single or multiple argument functions, and how the order of results are returned.
| Variant | Blocking | Ordered | Iterative | Accepts Multiple Arguments | Description |
|---|---|---|---|---|---|
Pool.map |
Yes | Yes | No | No | Applies a function to all items in the input iterable, returning results in order. |
Pool.map_async |
No | Yes | No | No | Similar to Pool.map, but returns a result object that can be checked later. |
Pool.imap |
No | Yes | Yes | No | Returns an iterator that yields results in order as they become available. |
Pool.imap_unordered |
No | No | Yes | No | Returns an iterator that yields results as they become available, order not guaranteed. |
Pool.starmap |
Yes | Yes | No | Yes | Applies a function to arguments provided as tuples, returning results in order. |
Pool.starmap_async |
No | Yes | No | Yes | Similar to Pool.starmap, but returns a result object that can be checked later. |
apply |
Yes | Yes | No | Yes | Runs a single callable function and blocks until the result is available. |
apply_async |
No | Yes | No | Yes | Runs a single callable function asynchronously and returns a result object. |
For this class, we will focus on pool.starmap() and describe the pool.apply_async() to highlight some of their capabilities and implementations.
map
The method of multiprocessing that we will be using utilizes the map method that we covered earlier in the lesson as pool.starmap(), or you can think of it as ‘start the map() function’. The method starts a new process for each item in the list and holds the results from each process in a list.
- Syntax: pool.map(func, iterable)
- Purpose: Applies a function to all items in a given iterable (e.g., list) and returns a list of results.
- Blocking: This method is blocking, meaning it waits for all processes to complete before moving on to the next line of code.
- Synchronous: Processes tasks synchronously and in order.
- Multiple Arguments: Designed to handle functions that take multiple arguments.
- Usage: Often used when you have a list of tasks to perform and want the results in the same order as the input.
What if you wanted to run different functions in parallel? You can be more explicit by using the pool.apply_async() method to execute different functions in parallel. This multiprocessing variant is useful when performing various tasks that do not depend on maintaining return order, does not interfere with each other, or is dependent on results from other tasks. Some examples are copying a Featureclasses to multiple places, performing data operations, and executing maintenance routines and much more.
apply_async
Instead of using the map construct, you assign each process to a variable, start the task, and then call .get() when you are ready for the results.
- Syntax: pool.apply_async(func, args=(), kwds={})
- Purpose: Schedules a single function to be executed asynchronously.
- Non-Blocking: This method is non-blocking, meaning it returns immediately with an ApplyResult object. It schedules the function to be executed and allows the main program to continue executing without waiting for the function to complete.
- Asynchronous: Processes tasks asynchronously, allowing for other operations to continue while waiting for the result.
- Multiple Arguments: Handles functions with a single argument or multiple arguments.
- Usage: It is used when you need to execute a function asynchronously and do not need to wait for the result immediately. You can collect the results later using the .get() method on the ApplyResult object. The .get() method retrieves the result of the function call that was executed asynchronously. If the function has already completed, it returns the result immediately. If the function is still running, it waits until the function completes and then returns the result.
For example, this is how you can have three different functions working at the same time while you execute other processes. You can call get() on any of the task when your needs the result of the process, or you can put all tasks into a list. When you put them in a list, the time it takes to complete is based on the longest running process. Note here that the parameters need to be passed as a tuple. Single parameters need to be passed as (arg, ), but if you need to pass more than one parameter to the function, the tuple is (arg1, arg2, arg3).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | with multiprocessing.Pool() as pool: p1 = pool.apply_async(functionA, (1param,)) # starts the functionA process p2 = pool.apply_async(functionB, (1param, 2param)) # starts the functionB process p3 = pool.apply_async(functionC, (1param,)) # starts the functionC process # run other code if desired while p1, p2, p3 executes. # we need the result from p3 so block further execution and wait for it to finish functionA_process = p3.get() ... # get the results from the processes within ordered as a list. # when we call .get() on the task, it becomes blocking so it will wait here until the last process in the list is # done executing. order_results = [p1.get(), p2.get(), …] |
When the list assigned to order_results is created and the .get() is called for each process, the results are stored in the list and can be retrieved by indexing or a loop.
1 2 3 4 5 | # After the processes are complete, iterate over the results and check for errors. for r in order_results: if r['errorMsg'] != None: print(f'Task {r["name"]} Failed with: {r["errorMsg"]}' else: ... |
What if the process run time is directly related to the amount of data being processed? For example, performing a calculation of a street at intervals of 20 feet for a whole County. Most likely, the dataset will have a wide range of street lengths. Short street segments will take milliseconds to compute, but the longer streets (those that are miles long) may take several minutes to calculate. You may not want to wait until the longest running process is complete to start working with the results since your short streets will be waiting and a number of your processors could be sitting idle until the last long calculation is done. By using the pool.imap_unordered or pool.imap methods, you can get the best performance gain since they work as an iterator and will return completed processes as they finish. Until the job list is completed, the iterator will ensure that no processor will sit idle, allowing many of the quicker calculated processes to complete and return while the longer processes continue to calculate. The syntax should look familiar since it is a simple for loop:
1 2 | for i in pool.imap_unordered(split_street_function, range(10)): print(i) |
We will focus on the pool.starmap() method for the examples and for the assignment since we will be simply applying the same function to a list of rasters or vectors. The multiple methods for multiprocessing are further described in the Python documentation here [9] and it is worth reviewing/ comparing them further if you have extra time at the end of the lesson.
1.6.6 Arcpy multiprocessing examples
1.6.6 Arcpy multiprocessing examples
Now that we have completed a non-ArcGIS parallel processing exercise, let's look at a couple of examples using ArcGIS functions. There are a number of caveats or gotchas to using multiprocessing with ArcGIS and it is important to cover them up-front because they affect the ways in which we can write our code.
Esri describe a number of best practices for multiprocessing with arcpy. These include:
- Use the “memory“ (Pro) or "in_memory" (legacy, but still works) workspaces to store temporary results because as noted earlier memory is faster than disk.
- Avoid writing to file geodatabase (FGDB) data types and GRID raster data types. These data formats can often cause schema locking or synchronization issues. That is because file geodatabases and GRID raster types do not support concurrent writing – that is, only one process can write to them at a time. You might have seen a version of this problem in arcpy previously if you tried to modify a feature class in Python that was open in ArcGIS. That problem is magnified if you have an FGDB and you’re trying to write many feature classes to it at once. Even if all of the feature classes are independent you can only write them to the FGDB one at a time.
- Use 64-bit. This isn’t an issue if we are writing code in ArcGIS Pro (although Esri does recommend using a version of Pro greater than 1.4) because we are already using 64-bit, but if you were planning on using Desktop as well, then you would need to use ArcGIS Server 10.5 (or greater) or ArcGIS Desktop with Background Geoprocessing (64-bit). The reason for this is that as we previously noted 64-bit processes can access significantly more memory and using 64-bit might help resolve any large data issues that don’t fit within the 32-bit memory limits of 4GB.
So bearing the top two points in mind we should make use of memory workspaces wherever possible and we should avoid writing to FGDBs (in our worker functions at least – but we could use them in our master function to merge a number of shapefiles or even individual FGDBs back into a single source).
1.6.6.1 Multiprocessing with raster data
1.6.6.1 Multiprocessing with raster data
There are two types of operations with rasters that can easily (and productively) be implemented in parallel: operations that are independent components in a workflow, and raster operations which are local, focal, or zonal – that is they work on a small portion of a raster such as a pixel or a group of pixels.
Esri’s Clinton Dow and Neeraj Rajasekar presented way back at the 2017 User Conference demonstrating multiprocessing with arcpy and they had a number of useful graphics in their slides which demonstrate these two categories of raster operations which we have reproduced here as they're still appropriate and relevant.
An example of an independent workflow would be if we calculate the slope, aspect and some other operations on a raster and then produce a weighted sum or other statistics. Each of the operations is independently performed on our raster up until the final operation which relies on each of them (see the first image below). Therefore, the independent operations can be parallelized and sent to a worker and the final task (which could also be done by a worker) aggregates or summarises the result. Which is what we can see in the second image as each of the tasks is assigned to a worker (even though two of the workers are using a common dataset) and then Worker 4 completes the task. You can probably imagine a more complex version of this task where it is scaled up to process many elevation and land-use rasters to perform many slope, aspect and reclassification calculations with the results being combined at the end.


An example of the second type of raster operation is a case where we want to make a mathematical calculation on every pixel in a raster such as squaring or taking the square root. Each pixel in a raster is independent of its neighbors in this operation so we could have multiple workers processing multiple tiles in the raster and the result is written to a new raster. In this example, instead of having a single core serially performing a square root calculation across a raster (the first image below) we can segment our raster into a number of tiles, assign each tile to a worker and then perform the square root operation for each pixel in the tile outputting the result to a single raster which is shown in the second image below.

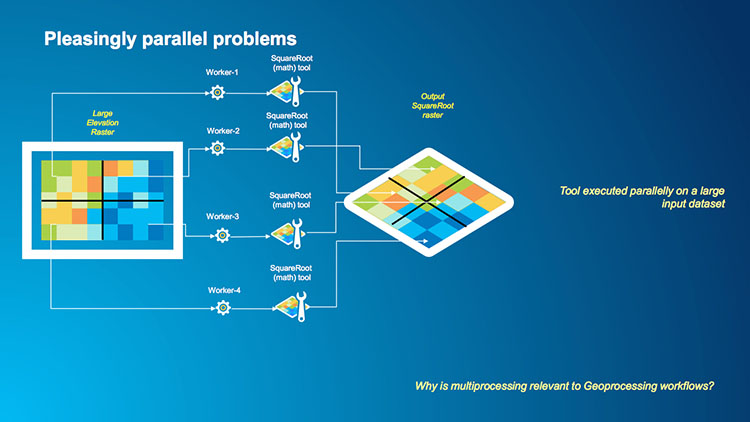
Let‘s return to the raster coding example that we used to build our ArcGIS Pro tool earlier in the lesson. That simple example processed a list of rasters and completed a number of tasks on each raster. Based on what you have read so far I expect that you have realized that this is also a pleasingly parallel problem.
Bearing in mind the caveats about parallel programming from above and the process that we undertook to convert the Cherry-O program, let's begin.
Our first task is to identify the parts of our problem that can work in parallel and the parts which we need to run sequentially.
The best place to start with this can be with the pseudocode of the original task. If we have documented our sequential code well, this could be as simple as copying/pasting each line of documentation into a new file and working through the process. We can start with the text description of the problem and build our sequential pseudocode from there and then create the multiprocessing pseudocode. It is very important to correctly and carefully design our multiprocessing solutions to ensure that they are as efficient as possible and that the worker functions have the bare minimum of data that they need to complete the tasks, use in_memory workspaces, and write as little data back to disk as possible.
Our original task was:
1 2 3 4 5 6 7 | Get a list of raster tilesFor every tile in the list: Fill the DEM Create a slope raster Calculate a flow direction raster Calculate a flow accumulation raster Convert those stream rasters to polygon or polyline feature classes. |
You will notice that I’ve formatted the pseudocode just like Python code with indentations showing which instructions are within the loop.
As this is a simple example we can place all the functionality within the loop into our worker function as it will be called for every raster. The list of rasters will need to be determined sequentially and we’ll then pass that to our multiprocessing function and let the map element of multiprocessing map each raster onto a worker to perform the tasks. We won’t explicitly be using the reduce part of multiprocessing here as the output will be a featureclass but reduce will probably tidy up after us by deleting temporary files that we don’t need.
Our new pseudocode then will look like :
1 2 3 4 5 6 7 8 9 10 | Get a list of raster tilesFor every tile in the list: Launch a worker function with the name of a rasterWorker: Fill the DEM Create a slope raster Calculate a flow direction raster Calculate a flow accumulation raster Convert those stream rasters to polygon or polyline feature classes. |
Bear in mind that not all multiprocessing conversions are this simple. We need to remember that user output can be complicated because multiple workers might be attempting to write messages to our screen at once and that can cause those messages to get garbled and confused. A workaround for this problem is to use Python’s logging library which is much better at handling messages than us manually using print statements. We haven't implemented logging in this sample solution for this script but feel free to briefly investigate it to supplement the print and arcpy.AddMessage functions with calls to the logging function. The Python Logging Cookbook [18] has some helpful examples.
As an exercise, attempt to implement the conversion from sequential to multiprocessing. You will probably not get everything right since there are a few details that need to be taken into account such as setting up an individual scratch workspace for each call of the worker function. In addition, to be able to run as a script tool the script needs to be separated into two files with the worker function in its own file. But don't worry about these things, just try to set up the overall structure in the same way as in the Cherry-O multiprocessing version and then place the code from the sequential version of the raster example either in the main function or worker function depending on where you think it needs to go. Then check out the solution linked below.
Click here for one way of implementing the solution [19]
When you run this code, do you notice any performance differences between the sequential and multiprocessor versions?
The sequential version took 96 seconds on the same 4-processor PC we were using in the Cherry-O example, while the multiprocessor version completed in 58 seconds. Again not 4 times faster as we might expect but nearly twice as fast with multiprocessing is a good improvement. For reference, the 32-processor PC from the Cherry-O example processed the sequential code in 110 seconds and the multiprocessing version in 40 seconds. We will look in more detail at the individual lines of code and their performance when we examine code profiling, but you might also find it useful to watch the CPU usage tab in Task Manager to see how hard (or not) your PC is working.
1.6.6.2 Multiprocessing with vector data
1.6.6.2 Multiprocessing with vector data
The best practices of multiprocessing that we introduced earlier are even more important when we are working with vector data than they are with raster data. The geodatabase locking issue is likely to become much more of a factor as typically we use more vector data than raster and often geodatabases are used more with feature classes.
The example we’re going to use here involves clipping a feature layer by polygons in another feature layer. A sample use case of this might be if you need to segment one or several infrastructure layers by state or county (or even a smaller subdivision). If I want to provide each state or county with a version of the roads, sewer, water or electricity layers (for example) this would be a helpful script. To test out the code in this section (and also the first homework assignment), you can again use the data from the USA.gdb geodatabase (Section 1.5) we provided. The application then is to clip the data from the roads, cities, or hydrology data sets to the individual state polygons from the States data set in the geodatabase.
To achieve this task, one could run the Clip tool manually in ArcGIS Pro but if there are a lot of polygons in the clip data set, it will be more effective to write a script that performs the task. As each state/county is unrelated to the others, this is an example of an operation that can be run in parallel.
Let us examine the code’s logic and then we’ll dig into the syntax. The code has two Python files [20]. This is important because when we want to be able to run it as a script tool in ArcGIS, it is required that the worker function for running the individual tasks be defined in its own module file, not in the main script file for the script tool with the multiprocessing code that calls the worker function. The first file called scripttool.py imports arcpy, multiprocessing, and the worker code contained in the second python file called multicode.py and it contains the definition of the main function mp_handler() responsible for managing the multiprocessing operations similar to the Cherry-O multiprocessing version. It uses two script tool parameters, the file containing the polygons to use for clipping (variable clipper) and the file to be clipped (variable tobeclipped). Furthermore, the file includes a definition of an auxiliary function get_install_path() which is needed to determine the location of the Python interpreter for running the subprocesses in when running the code as a script tool in ArcGIS. The content of this function you don't have to worry about. The main function mp_handler() calls the worker(...) function located in the multicode file, passing it the files to be used and other information needed to perform the clipping operation. This will be further explained below . The code for the first file including the main function is shown below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | import os, sysimport arcpyimport multiprocessingfrom multicode import worker# Input parametersclipper = arcpy.GetParameterAsText(0) if arcpy.GetParameterAsText(0) else r"C:\489\USA.gdb\States"tobeclipped = arcpy.GetParameterAsText(1) if arcpy.GetParameterAsText(1) else r"C:\489\USA.gdb\Roads"def mp_handler(): try: # Create a list of object IDs for clipper polygons arcpy.AddMessage("Creating Polygon OID list...") clipperDescObj = arcpy.Describe(clipper) field = clipperDescObj.OIDFieldName idList = [] with arcpy.da.SearchCursor(clipper, [field]) as cursor: for row in cursor: id = row[0] idList.append(id) arcpy.AddMessage(f"There are {len(idList)} object IDs (polygons) to process.") # Create a task list with parameter tuples for each call of the worker function. Tuples consist of the clippper, # tobeclipped, field, and oid values. jobs = [] for id in idList: # adds tuples of the parameters that need to be given to the worker function to the jobs list jobs.append((clipper,tobeclipped,field,id)) arcpy.AddMessage(f"Job list has {len(jobs)} elements.") # Create and run multiprocessing pool. # Set the python exe. Make sure the pythonw.exe is used for running processes, even when this is run as a # script tool, or it will launch n number of Pro applications. multiprocessing.set_executable(os.path.join(sys.exec_prefix, 'pythonw.exe')) arcpy.AddMessage(f"Using {os.path.join(sys.exec_prefix, 'pythonw.exe')}") # determine number of cores to use cpuNum = multiprocessing.cpu_count() arcpy.AddMessage(f"there are: {cpuNum} cpu cores on this machine") # Create the pool object with multiprocessing.Pool(processes=cpuNum) as pool: arcpy.AddMessage("Sending to pool") # run jobs in job list; res is a list with return values of the worker function res = pool.starmap(worker, jobs) # If an error has occurred within the workers, report it # count how many times False appears in the list (res) with the return values failed = res.count(False) if failed > 0: arcpy.AddError(f"{failed} workers failed!") arcpy.AddMessage("Finished multiprocessing!") except Exception as ex: arcpy.AddError(ex)if __name__ == '__main__': mp_handler() |
Let's now have a close look at the logic of the two main functions which will do the work. The first one is the mp_handler() function shown in the code section above. It takes the input variables and has the job of processing the polygons in the clipping file to get a list of their unique IDs, building a job list of parameter tuples that will be given to the individual calls of the worker function, setting up the multiprocessing pool and running it, and taking care of error handling.
The second function is the worker function called by the pool (named worker in this example) located in the multicode.py file (code shown below). This function takes the name of the clipping feature layer, the name of the layer to be clipped, the name of the field that contains the unique IDs of the polygons in the clipping feature layer, and the feature ID identifying the particular polygon to use for the clipping as parameters. This function will be called from the pool constructed in mp_handler().
The worker function will then make a selection from the clipping layer. This has to happen in the worker function because all parameters given to that function in a multiprocessing scenario need to be of a simple type that can be "pickled." Pickling data [21] means converting it to a byte-stream which in the simplest terms means that the data is converted to a sequence of bytes that represents the object in a format that can be stored or transmitted. As feature classes are much more complicated than that containing spatial and non-spatial data, they cannot be readily converted to a simple type. That means feature classes cannot be "pickled" and any selections that might have been made in the calling function are not shared with the worker functions.
We need to think about creative ways of getting our data shared with our sub-processes. In this case, that means we’re not going to do the selection in the master module and pass the polygon to the worker module. Instead, we’re going to create a list of feature IDs that we want to process and we’ll pass an ID from that list as a parameter with each call of the worker function that can then do the selection with that ID on its own before performing the clipping operation. For this, the worker function selects the polygon matching the OID field parameter when creating a layer with MakeFeatureLayer_management() and uses this selection to clip the feature layer to be clipped. The results are saved in a shapefile including the OID in the file's name to ensure that the names are unique.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | import arcpydef worker(clipper, tobeclipped, field, oid): """ This is the function that gets called and does the work of clipping the input feature class to one of the polygons from the clipper feature class. Note that this function does not try to write to arcpy.AddMessage() as nothing is ever displayed. param: clipper param: tobeclipped param: field param: oid """ try: # Create a layer with only the polygon with ID oid. Each clipper layer needs a unique name, so we include oid in the layer name. query = f"{field} = {oid}" tmp_flayer = arcpy.MakeFeatureLayer_management(clipper, f"clipper_{oid}", query) # Do the clip. We include the oid in the name of the output feature class. outFC = fr"c:\489\output\clip_{oid}.shp" arcpy.Clip_analysis(tobeclipped, tmp_flayer, outFC) # uncomment for debugging # arcpy.AddMessage("finished clipping:", str(oid)) return True # everything went well so we return True except: # Some error occurred so return False # print("error condition") return False |
Having covered the logic of the code, let's review the specific syntax used to make it all work. While you’re reading this, try visualizing how this code might run sequentially first – that is one polygon being used to clip the to-be-clipped feature class, then another polygon being used to clip the to-be-clipped feature class and so on (maybe through 4 or 5 iterations). Then once you have an understanding of how the code is running sequentially try to visualize how it might run in parallel with the worker function being called 4 times simultaneously and each worker performing its task independently of the other workers.
We’ll start with exploring the syntax within the mp_handler(...) function.
The mp_handler(...) function begins by determining the name of the field that contains the unique IDs of the clipper feature class using the arcpy.Describe(...) function (line 16 and 17). The code then uses a Search Cursor to get a list of all of the object (feature) IDs from within the clipper polygon feature class (line 20 to 23). This gives us a list of IDs that we can pass to our worker function along with the other parameters. As a check, the total count of that list is printed out (line 25).
Next, we create the job list with one entry for each call of the worker() function we want to make (lines 30 to 34). Each element in this list is a tuple of the parameters that should be given to that particular call of worker(). This list will be required when we set up the pool by calling pool.starmap(...). To construct the list, we simply loop through the ID list and append a parameter tuple to the list in variable jobs. The first three parameters will always be the same for all tuples in the job list; only the polygon ID will be different. In the homework assignment for this lesson, you will adapt this code to work with multiple input files to be clipped. As a result, the parameter tuples will vary in both the values for the oid parameter and for the tobeclipped parameter.
To prepare the multiprocessing pool, we first specify what executable should be used each time a worker is spawned (line 41). Without this line, a new instance of ArcGIS Pro would be launched by each worker, which is clearly less than ideal. Instead, this line uses the builtin sys.exec_prefix() variable and joins that path to the pythonw.exe executable. The next line prints out the path of the interpreter being used so you can verify that it is using the right one.
The code then sets up the size of the pool using the maximum number of processors in lines 45-49 (as we have done in previous examples) and then, using the starmap() method of Pool, calls the worker function worker(...) once for each parameter tuple in the jobs list (line 52).
Any outputs from the worker function will be stored in variable res as a list. These are the boolean values returned by the worker() function, True to indicate that everything went ok and False to indicate that the operation failed. If there is at least one False value in the list, an error message is produced stating the exact number of worker processes that failed (lines 57 to 58).
Let's now look at the code in our worker function worker(...) in the multicode file. As we noted in the logic section above, it receives four parameters: the full paths of the clipping and to-be-clipped feature classes, the name of the field that contains the unique IDs in the clipper feature class, and the OID of the polygon it is to use for the clipping.
Notice that the MakeFeatureLayer_management(...) function in line 18 is used to create a layer in memory which is a copy of the original clipper layer. This use of the memory layer is important in three ways: The first is performance – memory layers are faster; second, the use of an memory layer can help prevent any chance of file locking (although not if we were writing back to the file); third, selection only works on layers so even if we wanted to, we couldn’t get away without creating this layer.
The call of MakeFeatureLayer_management(...) also includes an SQL query string defined one line earlier in line 17 to create the layer with just the polygon that matches the oid that was passed as a parameter. The name of the layer we are producing here should be unique; this is why we’re adding {oid} to the name in the first parameter.
Now with our selection held in our memory, uniquely named feature layer, we perform the clip against our to-be-clipped layer (line 22) and store the result in outFC which we defined earlier in line 21 to be a hardcoded folder with a unique name starting with "clip_" followed by the oid. To run and test the code, you will most likely have to adapt the path used in variable outFC to match your PC.
The process then returns from the worker function and will be supplied with another oid. This will repeat until a call has been made for each polygon in the clipping feature class.
We are going to use this code as the basis for our Lesson 1 homework project. Have a look at the Assignment Page [22] for full details.
You can test this code out by running it in a number of ways. If you run it from ArcGIS Pro as a script tool, the ternary operator will use the input values from GetParameterAsText(), or if it is executed outside the Pro environment (executed from an IDE or from the commandline), the hard coded path will be used since arcpy.GetParameterAsText(i) will be None.
The final thing to remember about this code is that it has a hardcoded output path defined in variable outFC in the worker() function - which you will want to change, create and/or parameterize etc. so that you have some output to investigate. If you do none of these things then no output will be created.
When the code runs it will create a shapefile for every unique object identifier in the "clipper" shapefile (there are 51 in the States data set from the sample data) named using the OID (that is clip_1.shp - clip_59.shp).
1.6.6.3 The if __name__ == "__main__": revisited
Multiprocessing within a single script and if __name__ == "__main__":
In the examples we've used in the previous two sections, the worker function script has been separated from the main caller script and protected against possible infinite recursion or namespace conflicts by importing the worker script as a module (module.function()). However, what if you are limited to using a single script file, such as a Pro script tool that needs to be condensed for easy distribution? If we just add the worker function to the main script and try to reference that function as usual (function()), it will cause the multiprocessing module to import the entire main script, and will execute any top-level code (code not under the if __name__ == "__main__": block, functions, classes) for each new process. Other than infinite recursion, this can create conflicts in some custom Python environments such as Pro, leading to script failure, and it could possibly lock your PC up trying to open n** (exponentially for each process started) instances of Pro.
Remember that Python sets special variables when a script is executed. One of these is __name__, which is set to "__main__" when the script is run directly and set to the script's name (module) when it is imported. By importing the main script name within the if __name__ == "__main__": block, you ensure that the multiprocessing module correctly references functions that are within the imported script using the standard <main_script_name>.<function>() syntax and prevents the imported main script's code within the if __name__ == "__main__": from executing for each process.