Lesson 5: Working with Esri's Desktop Geodatabases
Overview
Overview
Critical to maintaining spatial databases is the job of ensuring the integrity of your spatial and nonspatial data. There are several behaviors that you can impose upon your data that will give you access to robust methods of assessing the integrity of existing data and of ensuring the integrity of newly created data. This lesson will expose you to some of those techniques.
Note that there are two sets of pages in this lesson; the first written for ArcGIS Pro and the second for ArcGIS Desktop (ArcMap). I strongly encourage you to work through the ArcGIS Pro pages since it is the more modern of the two packages. If you do that, there is no need to also work through the ArcMap pages, unless you're particularly interested. But if you have good reason to avoid Pro, such as having no experience with it or working in an environment where you're required to use ArcMap instead, then you have that option.
The point has been made that the best practice is to think through the implementation of your database design before you implement it. That philosophy certainly holds for what we will be covering in this lesson. However, in order to illustrate the concepts that we want to cover, it is advantageous to already have some existing data, both spatial and attribute. The scope of this lesson does not include a lot of tracing of spatial features and entering of attribute values. So, we will be applying the various techniques to existing data.
Objectives
At the successful completion of this lesson, students should be able to:
- understand attribute domains;
- understand subtypes;
- understand geodatabase topology.
Questions?
Conversation and comments in this course will take place within the course discussion forums.
Checklist
Checklist
Lesson 5 is one week in length. See the Canvas Calendar for specific due dates. To finish this lesson, you must complete the activities listed below:
- Work through Lesson 5.
- Complete the Projects that are at the end of each section of the lesson and upload the results as deliverables to the Project 5 Dropbox.
- Complete the Lesson 5 Quiz.
Attribute Domains
Attribute Domains
In Geography 484: GIS Database Development, you were introduced to attribute domains; however, it is possible to go through that course without having actually implemented them. So we will go over Coded Value Domains and Range Domains in the following section. Some of the material will be review for some of you, but even if you did work with attribute domains in Geography 484, you are apt to be exposed to functionality associated with them that was not covered in that course.
Follow this link to download the data for this part of the lesson: AttributeDomains.zip [1]
The zip archive contains two Esri File Geodatabases:
- AttributeDomainExercise.gdb
- AttributeDomainProject.gdb
A. Coded Value and Range Domains
A coded value domain allows you to choose from a list of values that are allowed in a field. A range domain allows you to specify a valid range for values in a numeric field. Both types of attribute domain thus provide means of enforcing data integrity.
- Create a new ArcGIS Pro project, then open the Catalog View (View > Catalog View) and browse to the Benchmarks feature class found in the AttributeDomainExercise.gdb file geodatabase. With the Benchmarks feature class selected, you should see the Details panel appear on the right side of the view. Click the Table tab to get a preview of the attribute table associated with the feature class. Take note of the Data Type of the ELEVATION field and of the BENCHSPOT field. Close the Feature Class Properties window.
The point features in the feature class represent locations of elevation benchmarks and spot elevations. The BENCHSPOT field is meant to hold an s for a spot elevation or a b for a benchmark location. A quick perusal of the values in that field shows that there are some errors. In addition, the elevation in this region ranges from about 1000 feet to about 1900 feet above sea level. We can see that there are some values in the ELEVATION field that violate that range. Our summer intern was not very meticulous.
Hover the mouse over the ELEVATION and BENCHSPOT field headings and take note of their data types.
Let's create and impose a coded value domain that will limit the possible entries in the BENCHSPOT field to s and b. And let's create and impose a range domain on the ELEVATION field that will allow us to verify that the values in that field are within the correct elevation range.
First, we will create a coded value domain named BenchSpotElev. - Browse back to the folder containing the AttributeDomainExercise.gdb file geodatabase, then right-click on the geodatabase and select Domains.
- In the first open slot under Domain Name, type BenchSpotElev. Then in the corresponding Description slot, enter a brief description of your choice.
- We know that the values in the existing BENCHSPOT field are Text type; so under the Field Type heading, select Text.
- We are dealing with a Text field, so under the Domain Type heading Coded Value Domain is really the only logical choice.
- Now in the panel to the right of the domain list, you should see a table with headings Code and Description. This is where we must enter our desired Code values (s and b) and their respective descriptions (spot elevation and benchmark).
Your Domains view should look like the image below. - If all is as it should be, hit the Save button; this is important to do before we move on.
Note: If you have a set of codes and associated descriptions in tabular form already, you can avoid the trouble of re-entering that information as outlined above by using the Table to Domain tool [2]. And if you are looking to automate the domain pieces of a workflow through either Model Builder or Python scripting, you may want to check out the other tools in the Domains toolset [3].
 Figure 5.1: The Domains view, showing configuration of the BenchSpotElev coded value domain.
Figure 5.1: The Domains view, showing configuration of the BenchSpotElev coded value domain. - Do not close the Domains view. We still need to create our Range domain for elevation. In a new empty row, assign a Domain Name of ElevationRange and enter something appropriate for the Description.
- Change the Field Type to Long and set the Domain Type to Range. Do you know why we need to set the Domain type to Long?
- Now, in the panel to the right, you will see spaces in which to enter the Minimum value and the Maximum value that we wish to use to constrain the entries in the ELEVATION field in the attribute table of our Benchmarks feature class. For Minimum, enter 1000, and for Maximum enter 1900.
- Your range domain settings should look like the image below. Make sure they do, and hit the Save button.
 Figure 5.2: The Domains view showing configuration of the ElevationRange range domain.
Figure 5.2: The Domains view showing configuration of the ElevationRange range domain. - Close the Domains view.
Now we need to apply the two new attribute domains to the BENCHSPOT and the ELEVATION fields. - Right-click on the Benchmarks feature class, and select Design > Fields.
- In the row for the ELEVATION field, access the dropdown list under the Domain heading and select the ElevationRange domain you just created.
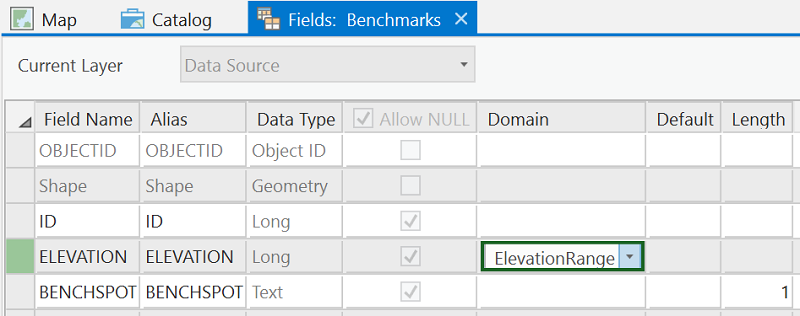 Figure 5.3: Assigning the ElevationRange domain to the ELEVATION field
Figure 5.3: Assigning the ElevationRange domain to the ELEVATION field - Click the Save button. Do not close the Fields view.
- Now perform the same operation to assign the BenchSpotElev domain to the BENCHSPOT field.
 Figure 5.4: Assigning the BenchSpotElev domain to the BENCHSPOT field
Figure 5.4: Assigning the BenchSpotElev domain to the BENCHSPOT field - Again, click the Save button.
And now you can close the Fields view.
Now, let's add the data to a map and see how the attribute domains help us control attribute data integrity. Before doing so, first a word about differences in attribute validation between ArcMap and ArcGIS Pro. In ArcMap, the default behavior is to allow values to be assigned to a field that are outside its domain. For example, you could enter an ELEVATION value greater than 1900, even after applying the ElevationRange domain. If that seems counter-intuitive to you, I would agree. However, ArcMap provides a Validate Features tool, which flags such invalid features so that you can correct them if you wish. And you also have the option of turning on automatic record validation, which will cause a warning to appear immediately if you attempt to enter a value outside a field's domain.
ArcGIS Pro, on the other hand, does not allow entries outside of a field's domain. I would say that's a sensible change. However, in a situation like this one, in which a domain has been applied after a feature class has already been populated with data, ArcMap's Validate Features tool provides a means to identify problematic values in the existing data, whereas ArcGIS Pro has no analogous tool.
- Add the Benchmarks feature class to the map and open its attribute table. You will probably notice immediately that the contents of the BENCHSPOT field appear different. While the code values that are a function of having assigned a coded value domain to a field are what are stored in the database, the description values are what display by default in the open attribute table. You can toggle this behavior off if you wish, clicking on the "hamburger" icon in the upper right of the table view and unchecking the Show domain and subtype descriptions option.
- Try changing one of the ELEVATION values to something greater than 1900 and note that it immediately reverts to the maximum allowed value (1900) per the domain we imposed.
- Click on a BENCHSPOT cell and note that you are limited to the two options defined in the BenchSpotElev domain (or Null).
- Next, click the Switch button to switch from no features selected to all features selected.
- Under the Edit tab, click the Attributes button. This will open a panel in which all of the benchmark features are listed by their ID value in the top of the panel and the full set of attributes for the currently highlighted feature is listed in the bottom of the panel.
- Click on ID 108 and note that its ELEVATION value is highlighted in red because that value is outside the field's domain. Click on ID 119 and note that both its ELEVATION and BENCHSPOT values are highlighted in red for the same reason.
 Figure 5.5: Attributes panel in ArcGIS Pro, showing attribute values violating attribute domain rules that are in place.
Figure 5.5: Attributes panel in ArcGIS Pro, showing attribute values violating attribute domain rules that are in place.
Clicking on features one at a time looking for attributes highlighted in red is not a particularly exciting prospect, especially if you're dealing with a lot more than the 25 features we have in this exercise. Better options would be to:
a. Use the Validate Features tool in ArcMap to isolate the problematic records, or
b. Use the Select By Attributes tool to find them (e.g., BENCHSPOT NOT IN ('b', 's') and ELEVATION < 1000 OR ELEVATION > 1900).
In any case, this problem of fixing invalid attribute values can be avoided if you apply domains when you first create the feature class!
B. Split and Merge Policies
Additional behaviors that can accompany attribute domains allow us to define what values get assigned to the field when a feature is split into two or when two features are merged into one. According to the Esri documentation, "...merge policies are not evaluated when merging features in the Editor. However, developers can take advantage of merge policies when writing their own merge implementations." The scope of this lesson does not include developer-level exercises, so we will visit only the use of split policies.
- In ArcGIS Pro's Catalog View, navigate to the AttributeDomainExercise.gdb file geodatabase and Preview the Roads feature class. We will be working with the SurfaceType field and the Length_Feet field.
Note that the Length_Feet field is a Float type field, and the SurfaceType field is a Text type field.
Let's create a coded value domain to use with the SurfaceType field and a range domain to use with Length_Feet field. - Right-click on the AttributeDomainExercise.gdb file geodatabase, and open its Domains view (Design > Domains).
- Click in the cell beneath your ElevationRange domain name, and name a new domain LengthFeet, and describe it as Length range in feet.
- Set the Field Type to Float (do you recall why?), and set the Domain Type to Range.
- Now, from the dropdown list under the Split policy heading, choose Geometry Ratio. This setting will make it so that the resulting values (in feet) in the Length_Feet field are in the same ratio as that of the lengths (the geometry) of the two new line features that resulted from the split operation.
Take note of the other two choices in the Split policy picklist. The Default Value is taken from the Default Value property that can be assigned to the field. We will see this below in the context of the coded value domain for the SurfaceType field. In this case, it would not make much sense to assign a default length to road segments, nor would it make sense to use the other choice, Duplicate, to assign the same length to each segment.
We will not interact with the Merge policy setting since we cannot take advantage of it, as mentioned above. But go ahead and look at the choices given if you are curious. - Let's define the Minimum value as 10 and the Maximum value as 264000. We are arbitrarily deciding that when we split a line feature representing a road that no road segment can be shorter than 10 feet or longer than 50 miles (264,000 feet).
- Check to be sure your settings are correct, and hit the Save button, but do not close the Domains view.
 Figure 5.6: Defining a domain with a Split Policy setting.
Figure 5.6: Defining a domain with a Split Policy setting. - Next, let's set up a domain for the road surface type values. Name it RoadSurface and describe it as Road surface material.
- Set the Field Type to Text. Note that this will force the Domain Type to be set to Coded Value Domain. But you knew that would be the case, right?
- Then set the Split policy to Default. As mentioned above, the default value is specified later in the properties of the SurfaceType field.
(The only Merge policy setting for a coded value domain is Default.) - Now, because this is a coded value domain, we need to enter the Code values and the corresponding Description values. Recall that we learned in the previous section that the codes are stored in the database (and the descriptions appear in the open table). As you noted when you previewed the data in the SurfaceType field of the Roads feature class, the existing data values are grass, gravel, asphalt, concrete and cobblestone. We will go ahead and retain those as the code values and set the description values to match. A "code" does not have to be a numeral or a single character (like the s and b used for the Benchmarks above). So go ahead and enter the five surface type category names in the right-hand panel as shown in the figure below. Take care to spell the code entries correctly. A misspelling would result in the existing values in the SurfaceType field not taking part in the domain.
- Hit the Save button when certain you have entered the correct settings -- the RoadSurface domain settings should look like this:
 Figure 5.7: RoadSurface domain settings, with the Split Policy set to Default.
Figure 5.7: RoadSurface domain settings, with the Split Policy set to Default. - Close the Domains view.
Now, let's assign the two new domains to the respective fields in the Roads feature class attribute table. - Still in Catalog View, right-click on the Roads feature class and select Design > Fields to open the Fields view.
- You've done this before. Under the Domain heading, click on the Length_Feet cell and select LengthFeet from the dropdown list.
 Figure 5.8: Assigning the LengthFeet domain to the Length_Feet field.
Figure 5.8: Assigning the LengthFeet domain to the Length_Feet field. - Hit Save.
- Next, assign the RoadSurface domain to the SurfaceType field. Note that the BenchSpotElev domain also appears in the picklist. Why, do you suppose?
- Also, under the Default heading, type asphalt. Recall that above we set the Split policy for the RoadSurface domain to Default Value. We are now specifying that default value; it needs to be one of the Code values that is part of the RoadSurface domain. Spell it correctly.
We can say that we know that most of the future work on the road system in this area will be done by the State, so the "asphalt" surface type is most apt to be involved; hence, we can set it as the default. Figure 5.9: Assigning the RoadSurface domain to the SurfaceType field, and setting the Default value to 'asphalt', and the Length to 25.
Figure 5.9: Assigning the RoadSurface domain to the SurfaceType field, and setting the Default value to 'asphalt', and the Length to 25. - Hit Save, then close the Fields view.
Now, let's see the behavior imposed on the data by two domains when we perform some edits. - Add the Roads feature class to the map.
- Open the Roads feature class attribute table.
- Select the U.S. Hwy 62 feature; you can click on it in the attribute table. Note the Length_Feet value (23128.34), and the SurfaceType value (concrete).
- Under the Edit tab, select the Split Tool and arbitrarily choose a point on the selected line feature and perform a split.
What happens? If you performed the split successfully, you should now see two separate U.S. Hwy 62 line features on the map and two U.S. Hwy 62 records in the attribute table.
What happened to the SurfaceType value for both of the features that are now the U.S. Hwy 62? Are they still "concrete"? Why not?
What are the Length_Feet values for the two features? Do they add up to 23128.34?
You can use the Undo tool in the upper right of the application window to revert to pre-split status if you want to compare the before and after. - Experiment with editing some of the other features if you wish.
- Save your project if you want, and quit ArcGIS Pro.
C. Project - Attribute Domains
For the homework deliverable for this part of the lesson, I am going to have you create two attribute domains to be assigned to existing fields in a feature class attribute table.
The data you will use is found in the AttributeDomainsProject.gdb file geodatabase. That geodatabase contains a single feature class named BuildingFootprints.
- Create an attribute domain and assign it to the Bldg_Type field (alias Building Type). The three allowed values for the field include C (commercial), R (residential), and P (public). NULL values are also allowed when the building category is not known.
- The Bldg_Story field (alias Building Stories) should contain values no larger than 7. Create and assign an attribute domain that will allow you to verify that values in that field do not violate that stipulation.
- Using either the Validate Features tool in ArcMap or your own queries in ArcGIS Pro, make and submit a screen capture showing features that have values outside the two domains. The image should show the selected offending records in the attribute table along with the query you used to select them.
- Submit your AttributeDomainsProject.gdb file geodatabase to the Lesson 5 drop box.
Following are some instructions on how to zip up both your image file and your AttributeDomainsProject.gdb file geodatabase.
In Lesson 5, we are dealing with File Geodatabases. Your AttributeDomainsProject.gdb geodatabase is a folder even though it has the .gdb extension on the name. To compress your file geodatabase along with your screen captured image in order to submit them, do the following:- In a Windows Explorer or a (My) Computer window, select both the geodatabase folder and your Word document file. The assumption is that the geodatabase and the image file are in the same folder making it possible to select them both.
- Then right-click on one of them and choose Send To | Compressed (zipped) Folder.
That will create a .zip file in the same folder. You need to turn in this .zip file. If, for some reason, you do not have the option to compress from within the Windows operating system, you can download a free application called 7-Zip [4]. It works well. - Name your .zip file appropriately, something like: <your name>_Lesson5Domains.zip.
D. Summary
Because attribute domains are stored in the geodatabase, they can be used by any dataset: feature class, table, subtype (covered in the next part of the lesson), within the geodatabase.
You can now move on to the Subtypes part of the lesson.
Credit for all screenshots: © Penn State is licensed under CC BY-NC-SA 4.0 [5]
Subtypes
Subtypes
In a situation where we have a lot of similar features, roads for example, that we want to easily assign separate attribute values to and symbolize differently, etc., we can designate them as what Esri calls subtypes. The alternative for managing such data and information would be to create separate feature classes for, in this example, each type of road. This practice can affect the performance and ease of use of the database.
Subtypes can be created for spatial features in a feature class or for objects (records) in a nonspatial, stand alone table. Subtypes can be created based on an existing field or a new field is created to hold the subtype values.
A subtype is defined by a code and a description. The codes are stored in a field in the attribute table and must be either Short or Long Integer values. Each code value is equated to a descriptive category. Sounds a lot like a coded value domain but, as you will see, they are not the same.
In our exercise example, we will be creating road subtypes from integer values that represent six different road type categories.
Follow this link to download the data for this part of the lesson: Subtypes.zip [6]
The zip archive contains two Esri file geodatabases:
- SubtypesExercise.gdb
- SubtypesProject.gdb
A. Assigning features to subtypes
We are going to place roads in subtype categories according to the values in an existing field that contains integer values that represent six road type categories.
- Open ArcGIS Pro.
- Navigate to the SubtypesExercise.gdb geodatabase in the Catalog pane and take note of its two attribute domains: MaintPeriod and RoadSurface.
- Now look into the Roads feature class that resides in the SubtypesExercise.gdb geodatabase. Investigate the attribute data and the properties of the fields. The data in the RoadType field will be the basis for our subtypes, and we will see how attribute domains are involved, too.
As mentioned above, an existing field containing either Long or Short Integer values can be used as the basis for establishing subtypes. The integer values 1 - 6 in the RoadType field represent the following categories of road. Each will become a subtype within our Roads feature class.- 1 - Primary Hwy
- 2 - Secondary Hwy
- 3 - Light Duty
- 4 - Unimproved
- 5 - 4WD
- 6 - Trail
- Let's use those descriptions to establish our subtypes. Open the Subtypes View for the Roads feature class (right-click, select Design > Subtypes).
- Click the Create/Manage button on the ribbon to begin creating the subtype.
- In the Manage Subtypes dialog that appears, select RoadType as the Subtype Field.
- Skipping over the Default Subtype for now, let us proceed to enter the Code values and their corresponding Description values using the list of road types above.
- The Default Subtype should be automatically set to Primary Hwy, assuming it was the first subtype you entered. But let's assume that we know that a roads improvement project will be beginning that will result in new Light Duty type roads being created. So, let's change the Default Subtype to Light Duty.
Your Manage Subtypes dialog should look like this: Figure 5.10: Defining the Roads subtypes using the Manage Subtypes dialog.
Figure 5.10: Defining the Roads subtypes using the Manage Subtypes dialog. - Click OK to finishing creating the subtypes.
Upon clicking OK, you should see new headings appear in the Subtypes View, one for each of the subtypes. The Light Duty heading will be in bold, indicating that it's the default subtype. Beneath each heading, you should see two columns: Domain and Default Value. As you can probably guess, this enables you to configure each subtype to have its own domain and default value, if desired. - Notice that, by default, the first subtype listed has become the Default Subtype. Let's change that.
- Under the Primary Hwy heading, make the following settings:
- specify the Default Value for the Surface Type field by selecting concrete from the dropdown list
- assign the MaintPeriod range domain to the MaintPeriod field (yes, the domain and the field have the same name)
- specify a Default Value of 2 (months) for the MaintPeriod field
- For each subtype, proceed to set a default value for the Surface Type field, assign the MaintPeriod range domain to the MaintPeriod field, and set a default value for the MaintPeriod field. Do so according to the following list.
- Primary Hwy | SurfaceType = concrete | MaintPeriod = 2 (already taken care of above)
- Secondary Hwy | SurfaceType = concrete | MaintPeriod = 2
- Light Duty | SurfaceType = asphalt | MaintPeriod = 6
- Unimproved | SurfaceType = cobblestone | MaintPeriod = 8
- 4WD | SurfaceType = gravel | MaintPeriod = 12
- Trail | SurfaceType = grass | MaintPeriod = 12
- Your Subtypes View should look like the following. (The green bars indicate settings that haven't been saved.)
 Figure 5.11 The Subtypes View with domains and default values set for each subtype.
Figure 5.11 The Subtypes View with domains and default values set for each subtype. - Be sure to click Save to apply your settings, then you may close the Subtypes View.
Now we will see what the implementation of the subtypes has put at our disposal. - If you haven't already, add the Roads feature class to the map.
One thing that is an implication of having subtypes assigned will be readily apparent. In the Contents pane, you will see that each subtype is listed along with a distinct symbolization. Go ahead and alter the symbol for each road type if you wish.
 Figure 5.12: The Contents pane in ArcGIS Pro, showing the subtypes of the Roads feature class.
Figure 5.12: The Contents pane in ArcGIS Pro, showing the subtypes of the Roads feature class. - Now, click the Edit tab, followed by the Create button. In the Create Features pane that opens, notice that each subtype has its own editing template. This serves to reinforce that each subtype is a category unto itself.
 Figure 5.13: The Create Features pane, showing that each subtype of the Roads feature class has an editing template.
Figure 5.13: The Create Features pane, showing that each subtype of the Roads feature class has an editing template. - Go ahead and choose one of the Roads subtype editing templates, then sketch a new line feature. It doesn't need to be a real road, you're simply testing out the subtype behavior. When you complete the sketch of the new line feature, a new record appears in the attribute table, complete with the default values pertinent to whatever subtype category you chose.
- Experiment further if you wish. Save your edits if you wish.
- Close ArcGIS Pro, saving your project if you desire.
So instead of creating separate feature classes for the different road types, we put the road line features into subtypes which gave us the ability to specify unique default values for each new feature of a different road type category, and to assign, or not, certain attribute domains to each category.
B. Project - Subtype Creation
As was mentioned above, subtypes can be created for objects (records) in a nonspatial table. In this homework project, that is what you will do.
Investigate the field structure and attribute data in the Encounters table residing in the SubtypesProject.gdb geodatabase. In addition to the OBJECTID field that is automatically created by the GIS, you will find the following five fields: ID, Encounter, Category, EducationLevel, and BloodAlcohol.
The values of 1 and 2 in the Encounter field represent Distant Encounters and Close Encounters respectively.
The descriptions of the values in the Category field are as follows:
- DE-1 - Nocturnal Light
- DE-2 - Daylight Disc
- DE-3 - Radar-visual
- CE-1 - Light/object in Proximity
- CE-2 - Physical Trace
- CE-3 - Occupant
The encounter data descriptions are based on information I took from the UFO Casebook site [7]: http://www.ufocasebook.com/Hynek.html
The values in the EducationLevel field are the number of years of school attended.
The values in the BloodAlcohol field are blood alcohol content measures. (Wikipedia Blood Alcohol Content Page [8]/ http://en.wikipedia.org/wiki/Blood_alcohol_content)
Here is what I want you to do for this project:
- Create an attribute domain for the three Distant Encounter categories (the DE values)
- Create an attribute domain for the three Close Encounter categories (the CE values)
- Create an attribute domain for the education level data
- Create an attribute domain for the blood alcohol content data
- Create subtypes based on the values in the Encounter field and associate the appropriate attribute domains with each
- Based on the data choose a default subtype (in spite of the small sample size)
- Based on the data specify default values for the two encounter subtypes (again, in spite of the small sample size)
When finished, zip your SubtypesProject.gdb geodatabase and submit it to the Project 5 Drop Box.
It can be problematic if the result of zipping your file geodatabase results in an archive name like Sloan_SubtypesProject.gdb.zip -- the embedded .gdb needs to be avoided.
Geodatabase Topology
Geodatabase Topology
A geodatabase topology is another construct that is stored within a geodatabase and gives us added control over assessing and maintaining the integrity of our spatial data.
Follow this link to download the data for this part of the lesson: Topology.zip [9]
The zip archive contains the following:
An Esri File Geodatabase: geodatabasetopol.gdb
A zip archive: TopologyProject.zip
Controlling spatial data integrity by imposing rules - Geodatabase Topology
A geodatabase topology provides a robust way of defining topological relationships among spatial features. It does so by analyzing coordinate locations of feature vertices both among features within a feature class and between features in multiple feature classes taking part in the topology. Therefore, it is not only important that all of the feature classes participating in a geodatabase topology be in the same coordinate system, but also that the measurement precision defined for each feature class be the same. To assure that this is the case, all feature classes that take part in a geodatabase topology must reside within what is known as a Feature Dataset. When a feature dataset is created, the coordinate system and precision are defined, and any subsequent feature class that is added to the feature dataset inherits that coordinate system and precision. In the exercise that follows, you will see that the precision is controlled by the Tolerance and Resolution settings. I encourage you to read more about these topics in the Topology in ArcGIS [10] entry in the ArcGIS Pro documentation.
A geodatabase topology is governed by topology "rules" that the user specifies, and those rules are based on knowledge of the relationships between and among the features that will be taking part in the topology. So, the onus is on the user to understand the data being created/edited in order that appropriate rules are specified.
The manifestation of a geodatabase topology is as a layer in the feature dataset. As such, the topology errors that it contains are symbolized just as are the features in any other map layer in ArcGIS. In the documentation, the Validate and fix geodatabase topology [11] topic provides an overview of the error fixing process along with links to the rules available for points, polylines, and polygons. If you are inclined to adorn your walls with GIS help guides, you may want to print the topology rules poster [12]. Whether you print it out or not. it offers a bit more in the way of graphic description and examples of the rules.
Once topology rules have been imposed on the data in a feature dataset. errors are discovered by "validating" the topology. Validation can be done on the entire visible extent of the data or on a smaller specified area. The latter technique allows you to just check an area that you have been editing, rather than the entire dataset. This can save time when the entire dataset is large.
As is mentioned above, one needs to be aware of how the features involved in a geodatabase topology relate to each other in order to be able to define appropriate topology rules to govern the creation of spatial data and aid in discovering errors in existing data. In the following exercise, we will be working with the data depicted in the image below, and I will be the arbitrary source of what is known about the relationships among the features in the four feature classes involved. We will be basing our choices of rules on the following:
- the polygons in the FDpolygon_1 feature class must have a single point feature within them
- all of the polygons in the FDpolygon_1 feature class must be within the polygons (there is only one) in the FDpolygon_2 feature class
- the polygons in the FDpolygon_1 feature class must have no gaps between them
- the polygons in the FDpolygon_1 feature class must not overlap
- all of the lines in the FDline feature class must be within the FDpolygon_2 polygons
- all of the lines in the FDline feature class cannot be joined to only one other line feature in the feature class (In topology parlance, the point where only two line segments meet is called a pseudo-node, or -vertex.)
- where lines in the FDline feature class meet, they must be snapped together (The end of a line feature that is not connected to another line feature is said to dangle.)

A. Create and interact with a Geodatabase Topology
- Open ArcGIS Pro.
- In the Catalog pane, navigate to your geodatabasetopol.gdb geodatabase.
- Within the geodatabasetopol.gdb geodatabase is a feature dataset named TopolExFeatureDataset. Verify that it contains four feature classes. You might also check the XY Coordinate System and the Tolerance and the Resolution of some of the feature classes to see that those settings are indeed the same for each feature class.
- Right-click on the TopolExFeatureDataset and select New > Topology. This will start the Create Topology Wizard.
- Accept the defaults for the name and for the cluster tolerance.
- Click the Select All button to include all of the feature classes in the feature dataset to the topology that we are creating.
We'll now assign a rank value to each feature class. The lower the number, the higher the rank. A high rank value indicates that positions of the features in that feature class are known more accurately, or that we do not want them to move relative to feature classes of lower rank during an editing operation. - Assign a value of 4 to the Number of XY Ranks property.
- Let's arbitrarily assign the following ranks (though nothing we do in the steps that follow will illustrate the effect of the rankings):
- 1 - FDpolygon_1
- 2 - FDpolygon_2
- 3 - FDline
- 4 - FDpoint
- Click Next. We're presented with an empty table of topology rules. Now, based on our knowledge and understanding of how the spatial data in the feature classes are topologically related, we can specify the rules that help us to ensure that those spatial relationships are maintained. Click in the empty row at the bottom of the table to add a new rule. Add each of the rules listed below, in all cases setting Feature Class 1 and a Rule, and sometimes setting Feature Class 2. Subtypes do not apply in this scenario.
- FDpoint | Must Be Properly Inside | FDpolygon_1
- FDpolygon_1 | Must Be Covered By Feature Class Of | FDpolygon_2
- FDpolygon_1 | Must Not Have Gaps
- FDpolygon_1 | Must Not Overlap
- FDline | Must Be Inside | FDpolygon_2
- FDline | Must Not Have Pseudo Nodes
- FDline | Must Not Have Dangles
- Click Next. You can review the choices just made.
Click Finish.
After processing for a few moments, you should have a new geodatabase topology layer named TopolExFeatureDataset_Topology in your TopolExFeatureDataset feature dataset. - In the Catalog pane, right-click on the topology layer and select Add to Current Map. This will add the topology layer and the four feature classes participating in the topology. (Yes, the data oddly cover much of the western hemisphere.I haven't the slightest idea where these shapes came from, please just go with it.)
The topology layer should display at the top of the Table of Contents list. This is important in order to be able to view the topology errors when they are symbolized. See Figure 5.16, below. - Alter the symbology and rearrange the order of the 4 feature class layers in order to clearly see the features they contain.
Do not label the features yet. - Under the Edit tab, in the Manage Edits group, you should see your geodatabase topology selected in the dropdown list. If not, go ahead and select it. Note that while we're experimenting with a geodatabase topology here, it is also possible to instead store topology rules as part of a map within a Pro project.
- Click on the Error Inspector
 button. The Error Inspector will display beneath the map by default.
button. The Error Inspector will display beneath the map by default.
 Figure 5.15: The Error Inspector pane.
Figure 5.15: The Error Inspector pane. - We're now going to validate the topological relationships according to the rules we defined. First, be certain you can view all of the features in the map display area. The validation will be carried out only for the features visible in the current map extent by default. Click the Validate button (part of the Error Inspector GUI).
Several features in the colors indicated in the Table of Contents pane for the topology layer should be visible. We will spend the next several steps investigating what they tell us.
(The image below also shows the results of the feature labeling we will do in the next step.)
 Figure 5.16: The map, showing the TopolExFeatureDataset_Topology geodatabase topology, along with the layers that take part in the geodatabase topology. The image also shows the labeling of the features.
Figure 5.16: The map, showing the TopolExFeatureDataset_Topology geodatabase topology, along with the layers that take part in the geodatabase topology. The image also shows the labeling of the features. - Before we proceed, let's label the features in the data frame with the values in the OBJECTID field of each feature class. For each layer, right-click, select Labeling Properties, set the Expression to $feature.OBJECTID, then right-click on the layer again and select Label.
- Keep in mind what you read above, at the beginning of this section, in regard to what are the desired spatial relationships of the features in the dataset we are working with.
The Error Inspector shows errors associated with all rules by default, but we can limit that to just a particular rule. Next to the Filter heading, click the Rules button, and select FDline - Must Not Have Pseudo Nodes.
The full list of 19 errors will be reduced to 2. - Click on the row in the Error Inspector that holds the error entry where Feature 1 is 10 and Feature 2 is 16. The Feature # is the value of the OBJECTID field. This is why I had you label the features with the values in the OBJECTID field.
This type of error is represented by a Point Error symbol, the pink square. When you click the row in the Error Inspector, the pink square that separates line features 10 and 16 will turn yellow, thus indicating the location of the instance that violates this particular topological rule, that each line feature in the FDline feature class should share an end point with at least two other lines. The highlighted error indicates a situation where only two line features are sharing an endpoint. Note that you are also shown a zoomed-in look at the error in the right-hand pane of the Error Inspector. - If you right-click on the line entry in the Error Inspector, it will bring up a list (see Figure 5.17 below) from which you can choose to, among several things, Merge or Merge To Largest. These are two choices in the context of this particular type of error for fixing the problem. The Merge choice gives you an option to choose one of the two line features. The implication is that the attributes associated with the chosen line will be those retained for the new single line feature that results from the Merge.
Go ahead and experiment with the choices in the list. You can always Undo any change you make. (Ctrl-Z, or use the Undo button in the upper left of the application window) Figure 5.17: The menu that comes up when you right-click on an entry of the Error Inspector pane.
Figure 5.17: The menu that comes up when you right-click on an entry of the Error Inspector pane. - There is a second violation of the Must Not Have Pseudo Nodes error. Highlight it via the Error Inspector. You'll see that it is where line features 8, 14, and 15 are supposed to meet. If you zoom in far enough on that intersection, you will see that line 8 is not snapped at the intersection of lines 14 and 15.
- It turns out that one of our other rules would have also highlighted an error in that same area. Do you know which one? Click the Rules button again and select FDline - Must Not Have Dangles.
- In the list of errors, click the row where Feature 1 is equal to 8. That should also highlight a vertex in the vicinity of where line feature 8 is supposed to be snapped at the intersection of lines 14 and 15. Which vertex is highlighted? It is the end vertex of line feature 8.
The list of Must Not Have Dangles errors contains 10 entries. It is important to realize that not all dangling line feature endpoints are actually errors. It is acceptable to have dead end streets, for example. - It is also important to realize that the Must Not Have Dangles rule only pertains to features in a single layer. If you click through the list of dangle errors, you will see that three of the entries on the list are where line features 7, 8, and 9 meet the corners of polygon 11 (the FDpolygon_2 feature). If you do some investigating, you will find that the end of line 7 is indeed snapped to the corner vertex of polygon 11. Even so, the geodatabase topology still flags it as a possible error.
- Now, let's look at the FDpolygon_1 - Must Not Have Gaps error results.
Select it from the Rules picklist in the Error Inspector. You should see two results listed in the Error Inspector represented by the Line Error symbol. - One of the Error Inspector entries, when chosen from the list, will show the result depicted in the image below (Figure 5.18).
Click on the entries until you find it.
Part of the description of this topology rule includes the following: "An error will always exist on the perimeter of the surface. You can either ignore this error or mark it as an exception." Figure 5.18: The view of the FDpolygon_1 data after you choose the desired Must Not Have Gaps entry in the Error Inspector.
Figure 5.18: The view of the FDpolygon_1 data after you choose the desired Must Not Have Gaps entry in the Error Inspector. - Let's mark this as an exception.
Right-click on the error entry in the Error Inspector table and choose Mark As Exception. An exclamation point icon will appear in the Exception column and if you select a different error, you'll see that what had been a pink outline, indicating an error, has changed to a green outline, indicating that it's been marked as an exception. - Select the error that highlights the boundary between polygons 2 and 5, then click the Error Inspector's Zoom To button. Toggle the topology layer's visibility off for the moment so that you're able to see the polygon boundaries. When you zoom in far enough, you should discover a gap between FDpolygon_1 polygons 2 and 5. Someone did not do a good job of making sure the FDpolygon_1 features shared boundaries.
Let's stick with the FDpolygon_1 polygon layer and perform an edit. While we are at it, we will learn how to highlight areas in our data that have been modified/edited. These "dirty areas," as they are referred to, let us know that we should validate the topology again. - Zoom back out to Full Extent.
In the Error Inspector, select the FDpolygon_1 - Must Not Overlap rule. There should be two errors. We are going to focus on the one involving polygons 2 and 3. - Again making sure the topology layer is turned off, zoom in on the location of the overlap error between polygons 2 and 3 until you have a good view of the overlap. You could elect to change the display of the layer to "Hollow" in order to see the overlap more definitely.
- Let's rectify the overlap using the canned error correction choice provided by the Error Inspector. Right-click on the error in the Error Inspector and select Merge from the menu.
- In the Merge window that opens, click on each of the two entries. Doing so will cause the polygon that the overlap area will be merged with to be flicker-highlighted.
- Choose the first of the two -- for polygon feature 2, and then click the Merge button.
- If you still have the display of the TopolExFeatureDataset_Topology layer un-checked, check the box now. Also turn on the display of the Dirty Areas Polygon 3 should be highlighted in the hatch pattern, indicating that it is a dirty area -- that a change has been made since the topology rules were last validated.
- Click the Validate button again. The hatched area should disappear, indicating that the error has been correctly dealt with as far as our topology rules are concerned. Also note that there should be only one overlap error left.
- You should save your edits now (Edit > Save).
- Deliverable- I want to see that you were able to perform the correction we just went though, so zip up your geodatabasetopol.gdb geodatabase and upload it to the Project 5 Drop Box.
You should be getting a feel for how to interact with the Error Inspector.
Go ahead and spend some time investigating the other rules infractions to see if you can determine the reasons for the other error symbols that you see on the map.
- Why is there a Point Error at the bottom-left corner of the FDpolygon_1 polygon 5 feature (point 3)?
- Why is line 9 highlighted?
- etc.
If you want, attempt to correct some of the other errors. Not all of them (like the gap we found between the two polygons) have canned fixes via the Error Inspector. So if you are pining away for a chance to do some editing, be my guest.
I leave it up to you to choose whether or not to save the project, and any edits you make.
B. Using topology editing tools with shared polygon boundaries
With a geodatabase topology in place, there are certain tools at your disposal that enable you to maintain topological relationships when you make edits to spatial data. Here, we contrast editing a shared polygon boundary with and without having a geodatabase topology set up. It is important to realize that the "shared" boundary between two polygons actually is a duplicate set of line segments, each polygon boundary exists as complete and independent from the adjacent polygon. So, when a shared boundary needs to be edited, one must actually edit the boundaries of two polygons.
- First, we will look at the case where we have no topology imposed on the data, and we attempt to edit a shared polygon boundary with the Vertices tool
 . The images below illustrate what happens. Because the edit is conducted with No Topology, only one of the polygon's vertices can be moved at a time. The images depict a simple case, but think of a situation where three or four polygons share a common corner vertex.
. The images below illustrate what happens. Because the edit is conducted with No Topology, only one of the polygon's vertices can be moved at a time. The images depict a simple case, but think of a situation where three or four polygons share a common corner vertex.
 Figure 5.19: Two polygon features in a geodatabase feature class that share a boundary.
Figure 5.19: Two polygon features in a geodatabase feature class that share a boundary. Figure 5.20: The result of editing/moving one vertex when conducted with No Topology.
Figure 5.20: The result of editing/moving one vertex when conducted with No Topology. - With a topology in place, the capabilities of the Vertices tool are extended a bit. In the Modify Features pane to the right of the map, an Edges tab appears in addition to the Features tab. By clicking the Edges tab, you can then select a shared edge that you'd like to modify. In the first of the two figures below, the shared edge is shown selected after having clicked the Edges tab. In the second figure, you can see that the same vertex moved in Figure 5.20 has been moved again. This time, both polygon boundaries are edited at the same time.
 Figure 5.21: With a geodatabase topology in place, and the shared boundary selected prior to moving the vertex.
Figure 5.21: With a geodatabase topology in place, and the shared boundary selected prior to moving the vertex. Figure 5.22: The result of editing/moving two shared vertices when a geodatabase topology is in place.
Figure 5.22: The result of editing/moving two shared vertices when a geodatabase topology is in place.
C. Project - Given a single feature class in a geodatabase, set up a geodatabase topology and deal with a single class of error
Because this is not a course in inputting and editing spatial and attribute data, we are choosing to focus on what needs to be done to prepare to implement a geodatabase topology. There will be some errors in spatial data to repair, but it involves going over ground already covered in section A of the lesson.
Unzip the TopologyProject.zip archive. The archive contains a folder named TopologyProject. Within that folder is a geodatabase (TopologyProject.gdb) and a georeferenced image of a map (with ancillary files).
The BuildingFootprints feature class contains some instances of polygon overlap that need to be repaired.
In order for you to accomplish finding and repairing the errors in the BuildingFootprints feature class, you are going to have to create and employ a geodatabase topology. You know from section A how to create a geodatabase topology, and you know that in order to do so, the data in question has to reside within a feature dataset. What we did not explicitly go over in the lesson was how to (1) create a feature dataset, and (2) how to get existing data, in this case the feature class contained in the TopologyProject.gdb, into a feature dataset that we create. But that's what I want you to do. Given that Geography 484 or comparable experience was the prerequisite for taking this course, you should be able to do it.
Once you have accomplished that, proceed to find and correct the overlapping building footprint polygons. All of the offending features will be in the area covered by the included georeferenced map image. You can use it as reference to make sure you are performing the corrections to the polygons correctly.
When you finish, zip up your version of the TopologyProject.gdb and upload it to the Lesson 5 Drop Box.
Credit for all screenshots: © Penn State is licensed under CC BY-NC-SA 4.0 [5]
Attribute Domains (for ArcMap)
Attribute Domains
In Geography 484: GIS Database Development, you were introduced to attribute domains; however, it is possible to go through that course without having actually implemented them. So we will go over Coded Value Domains and Range Domains in the following section. Some of the material will be review for some of you, but even if you did work with attribute domains in Geography 484, you are apt to be exposed to functionality associated with them that was not covered in that course.
Follow this link to download the data for this part of the lesson: AttributeDomains.zip [1]
The zip archive contains two Esri File Geodatabases:
- AttributeDomainExercise.gdb
- AttributeDomainProject.gdb
A. Coded Value and Range Domains
A coded value domain allows you to choose from a list of values that are allowed in a field. A range domain allows you to specify a valid range for values in a numeric field. Both types of attribute domain thus provide means of enforcing data integrity.
- Open ArcCatalog (the standalone application, not the Catalog window in ArcMap), and look at the Properties of the Benchmarks feature class found in the AttributeDomainExercise.gdb file geodatabase. Right-click and choose Properties. Click the Fields tab and take note of the Data Type of the ELEVATION field and of the BENCHSPOT field. Close the Feature Class Properties window.
Also Preview the feature class, use the picklist at the bottom of the Preview pane to view the contents of the attribute Table.
The point features in the feature class represent locations of elevation benchmarks and spot elevations. The BENCHSPOT field is meant to hold an s for a spot elevation or a b for a benchmark location. A quick perusal of the values in that field shows that there are some errors. In addition, the elevation in this region ranges from about 1000 feet to about 1900 feet above sea level. We can see that there are some values in the ELEVATION field that violate that range. Our summer intern was not very meticulous.
Let's create and impose a coded value domain that will limit the possible entries in the BENCHSPOT field to s and b. And let's create and impose a range domain on the ELEVATION field that will allow us to verify that the values in that field are within the correct elevation range.
First, we will create a coded value domain named BenchSpotElev. - Right-click on the name of the AttributeDomainExercise.gdb file geodatabase and select Properties. This will open the Database Properties window.
Select the Domains tab. - In the first open slot under Domain Name, type BenchSpotElev. Then in the corresponding Description slot, enter a brief description of your choice.
- Look at the entries in the Domain Properties area. The cell next to Domain Type will let you select either Coded Values or Range. We are creating a coded value domain, so make sure it is set to the Coded Values choice.
- We know that the values in the existing BENCHSPOT field are Text type; so now in the Domain Properties area, click in the cell to the right of Field Type, and from the picklist choose Text. While we are here, note that based on the choices in the picklist, you can create a coded value domain that can be used with six different field data types.
After setting the Field Type to Text, the Domain Type will no longer present the Range choice; a Range domain can only be a numeric type. - Now in the Coded Values area, we must enter both Code values and corresponding Description values. The values s and b will be our code values, and the respective descriptions will be spot elevation and benchmark.
Your Database Properties window should look like the image below. Your domain Description may be different, and hopefully without the typo that mine has. - If all is as it should be, hit the Apply button; this is important to do before we move on.
Note: If you have a set of codes and associated descriptions in tabular form already, you can avoid the trouble of re-entering that information as outlined above by using the Table to Domain tool [2]. And if you are looking to automate the domain pieces of a workflow through either Model Builder or Python scripting, you may want to check out the other tools in the Domains toolset [3].
 Figure 5.1: The Database Properties dialog > Domains tab configuration for the BenchSpotElev coded value domain.
Figure 5.1: The Database Properties dialog > Domains tab configuration for the BenchSpotElev coded value domain. - Do not close the Database Properties window. We still need to create our Range domain for elevation. Go back to the Domain Name column and add an entry named ElevationRange and enter something appropriate for the Description.
- Change the Field Type to Long Integer and set the Domain Type to Range. Do you know why we need to set the Domain type to Long Integer?
- Now you will see spaces in which to enter the Minimum value and the Maximum value that we wish to use to constrain the entries in the ELEVATION field in the attribute table of our Benchmarks feature class. For Minimum value, enter 1000, and for Maximum value enter 1900.
- Your range domain setting should look like those below. Make sure they do, and hit the Apply button.
 Figure 5.2: The Database Properties dialog > Domains tab configuration for the ElevationRange range domain.
Figure 5.2: The Database Properties dialog > Domains tab configuration for the ElevationRange range domain. - Hit the OK button to close the Database Properties window.
Now we need to apply the two new attribute domains to the BENCHSPOT and the ELEVATION fields. - Right-click on the Benchmarks feature class, and select Properties.
Select the Fields tab if necessary. - Click on the ELEVATION field name. In the Field Properties area, there should be a Domain property.
Click in the cell next to it, and select the ElevationRange domain. Figure 5.3: Assigning the ElevationRange domain to the ELEVATION field.
Figure 5.3: Assigning the ElevationRange domain to the ELEVATION field. - Click the Apply button. Do not close the Feature Class Properties window.
- Now, click on the name of the BENCHSPOT field.
In the cell next to the Domain property, choose the BenchSpotElev domain. Figure 5.4: Assigning the BenchSpotElev domain to the BENCHSPOT field, and setting the Length property to 1.
Figure 5.4: Assigning the BenchSpotElev domain to the BENCHSPOT field, and setting the Length property to 1. - Again, click the Apply button.
And you can click the OK button to dismiss the window.
Now, let's go into ArcMap and see how the attribute domains help us control attribute data integrity. In an editing session, with the desired features selected, we can find out if there are any attribute entries that violate the specifications of the attribute domains we established. - Open ArcMap.
- Add the Benchmarks feature class to the data frame and open its attribute table. You will probably notice immediately that the contents of the BENCHSPOT field appear different. While the code values that are a function of having assigned a coded value domain to a field are what are stored in the database, the description values are what display by default in the open attribute table. You can control the display by going into the Table Properties menu (the icon in the upper left), selecting Appearance and checking or un-checking the box for Display coded value domains and subtype descriptions.
- Start an editing session. Add the Editor toolbar if necessary.
- From the Table Options list in the open attribute table, choose Select All.
- Now, from the Editor drop down list on the Editor toolbar, select Validate Features. Two things will happen. You will see a popup that lets you know that there are five features with attribute values in violation of the attribute domain rules, and the selected set of features will be reduced to those five offending features.
At this point, you could go ahead and deal with the errors by editing the values in the attribute table.
 Figure 5.5: Popup showing how many attribute values violate attribute domain rules that are in place.
Figure 5.5: Popup showing how many attribute values violate attribute domain rules that are in place. - When it comes to adding additional features and corresponding attributes with the coded value domain in place for the BENCHSPOT field, a drop-down list from which either valid value can be chosen will appear when that cell in the attribute table is edited. When it comes to the ELEVATION field, you can either periodically perform the Validate Features step as we did above, or you can go into the Table Options menu > choose Appearance | and check the box for Automatically validate records. With that set, a warning will appear any time you enter an elevation value that is not within the specified range.
Take some time and experiment. - Close ArcMap. You can save your map document if you wish. You may want to return to it.
B. Split and Merge Policies
Additional behaviors that can accompany attribute domains allow us to define what values get assigned to the field when a feature is split into two or when two features are merged into one. According to the Esri documentation, "...merge policies are not evaluated when merging features in the Editor. However, developers can take advantage of merge policies when writing their own merge implementations." The scope of this lesson does not include developer-level exercises, so we will visit only the use of split policies.
- In ArcCatalog, navigate to the AttributeDomainExercise.gdb file geodatabase and Preview the Roads feature class. We will be working with the SurfaceType field and the Length_Feet field.
View the Feature Class Properties of the Roads feature class, and see that the Length_Feet field is a Float type field, and the SurfaceType field is a Text type field.
Let's create a coded value domain to use with the SurfaceType field and a range domain to use with Length_Feet field. - Right-click on the AttributeDomainExercise.gdb file geodatabase, and go to Properties.
Select the Domains tab. - Click in the cell beneath your ElevationRange domain name, and name a new domain LengthFeet, and describe it as Length range in feet.
- In the Domain Properties area, set the Field Type to Float (do you recall why?), and set the Domain Type to Range.
- Let's define the Minimum value as 10 and the Maximum value as 264000. We are arbitrarily deciding that when we split a line feature representing a road that no road segment can be shorter than 10 feet or longer than 50 miles (264,000 feet).
- Now, from the picklist in the cell next to Split policy, choose Geometry Ratio. This setting will make it so that the resulting values (in feet) in the Length_Feet field are in the same ratio as that of the lengths (the geometry) of the two new line features that resulted from the split operation.
Take note of the other two choices in the Split policy picklist. The Default Value is taken from the Default Value property that can be assigned to the field. We will see this below in the context of the coded value domain for the SurfaceType field. In this case, it would not make much sense to assign a default length to road segments, nor would it make sense to use the other choice, Duplicate, to assign the same length to each segment.
We will not interact with the Merge policy setting since we cannot take advantage of it, as mentioned above. But go ahead and look at the choices given if you are curious. - Check to be sure your settings are correct, and hit the Apply button, but do not close the Database Properties window.
 Figure 5.6: Domain Properties > Domains tab showing settings to create LengthFeet range domain, with the Split policy property set to Geometry Ratio.
Figure 5.6: Domain Properties > Domains tab showing settings to create LengthFeet range domain, with the Split policy property set to Geometry Ratio. - Next, let's set up a domain for the road surface type values. Name it RoadSurface and describe it as Road surface material.
- Set the Field Type to Text. Note that this will force the Domain Type to be set to Coded Values. But you knew that would be the case, right?
- Then set the Split policy to Default Value. As mentioned above, the default value is specified later in the properties of the SurfaceType field.
(The only Merge policy setting for a coded value domain is Default value.) - Now, because this is a coded value domain, we need to enter the Code values and the corresponding Description values. Recall that we learned in the previous section that the codes are stored in the database (and the descriptions appear in the open table). As you noted when you previewed the data in the SurfaceType field of the Roads feature class the existing data values are grass, gravel, asphalt, concrete and cobblestone. We will go ahead and retain those as the code values and set the description values to match. A "code" does not have to be a numeral or a single character (like the s and b used for the Benchmarks above). So go ahead and enter the five surface type category names in both the Code list and the Description list of the Coded Values area. Take care to spell the code entries correctly. A misspelling would result in the existing values in the SurfaceType field not taking part in the domain.
- Hit the Apply button when certain you have entered the correct settings -- the RoadSurface domain settings should look like this:
 Figure 5.7: Domain Properties > Domains tab showing settings to create RoadSurface coded value domain, with the Split policy set to Default Value.
Figure 5.7: Domain Properties > Domains tab showing settings to create RoadSurface coded value domain, with the Split policy set to Default Value. - Hit the OK button to dismiss the Database Properties window.
Now, let's assign the two new domains to the respective fields in the Roads feature class attribute table. - Still in ArcCatalog, right-click on the Roads feature class and select Properties to open the Feature Class Properties window.
- You've done this before, In the Field Name list, click on the Length_Feet field, then in the Field Properties area assign the LengthFeet domain to the Domain property of the field.
 Figure 5.8: Assigning the LengthFeet domain to the Length_Feet field.
Figure 5.8: Assigning the LengthFeet domain to the Length_Feet field. - Hit Apply.
- Next, click the SurfaceType field, and assign the RoadSurface domain to it. Note that the BenchSpotElev domain also appears in the picklist. Why, do you suppose?
- Also, in the cell next to Default Value in the Field Properties area, type asphalt. Recall that above we set the Split policy for the RoadSurface domain to Default Value. We are now specifying that default value; it needs to be one of the Code values that is part of the RoadSurface domain. Spell it correctly.
We can say that we know that most of the future work on the road system in this area will be done by the State, so the "asphalt" surface type is most apt to be involved; hence, we can set it as the default. Figure 5.9: Assigning the RoadSurface domain to the SurfaceType field, and setting the Default Value to 'asphalt', and the Length property to 25.
Figure 5.9: Assigning the RoadSurface domain to the SurfaceType field, and setting the Default Value to 'asphalt', and the Length property to 25. - Hit Apply, then hit OK.
Now, in ArcMap, let's see the behavior imposed on the data by two domains when we perform some edits. - Open ArcMap, and add the Roads feature class to the data frame.
- Open the Roads feature class attribute table.
- Start an editing session.
- Select the U.S. Hwy 62 feature; you can click on it in the attribute table. Note the Length_Feet value (23128.34), and the SurfaceType value (concrete).
- Select the Split Tool from the Editor toolbar, and arbitrarily choose a point on the selected line feature and perform a split. You might want to invoke the Edge Snapping to aid you.
What happens? If you go to select the U.S. Hwy 62 line feature, it should be in two parts, and there should also be a new record in the attribute table at the bottom.
What happened to the SurfaceType value for both of the features that are now the U.S. Hwy 62? Are they still "concrete"? Why not?
What are the Length_Feet values for the two features? Do they add up to 23128.34?
You can use the Undo tool on the standard toolbar to revert to pre-split status if you want to compare the before and after. - Experiment with editing some of the other features if you wish.
- Save your map document if you want, and quit ArcMap.
C. Project - Attribute Domains
For the homework deliverable for this part of the lesson, I am going to have you create two attribute domains to be assigned to existing fields in a feature class attribute table.
You will use the behavior functionality that the domains give you to find several attribute errors that reside in the dataset.
The data you will use is found in the AttributeDomainsProject.gdb file geodatabase. That geodatabase contains a single feature class named BuildingFootprints.
- Create an attribute domain for the Bldg_Type field (alias Building Type). The three allowed values for the field include C (commercial), R (residential), and P (public). NULL values are also allowed when the building category is not known.
- The Bldg_Story field (alias Building Stories) should contain values no larger than 7. Create an attribute domain that will allow you to verify that values in that field do not violate that stipulation.
- Make and submit a screen capture showing the results of discovering the errors that exist in the two fields in question. The image should show (1) the selected offending records in the attribute table, and (2) the popup showing the number of offending records.
- Submit your AttributeDomainsProject.gdb file geodatabase to the Lesson 5 drop box.
Following are some instructions on how to zip up both your image file and your AttributeDomainsProject.gdb file geodatabase.
In Lesson 5, we are dealing with File Geodatabases. Your AttributeDomainsProject.gdb geodatabase is a folder even though it has the .gdb extension on the name. To compress your file geodatabase along with your screen captured image in order to submit them, do the following:- In a Windows Explorer or a (My) Computer window, select both the geodatabase folder and your Word document file. The assumption is that the geodatabase and the image file are in the same folder, making it possible to select them both.
- Then right-click on one of them and choose Send To | Compressed (zipped) Folder.
That will create a .zip file in the same folder. You need to turn in this .zip file. If, for some reason, you do not have the option to compress from within the Windows operating system, you can download a free application called 7-Zip [4]. It works well. - Name your .zip file appropriately, something like: <your name>_Lesson5Domains.zip.
D. Summary
Because attribute domains are stored in the geodatabase, they can be used by any dataset: feature class, table, subtype (covered in the next part of the lesson), within the geodatabase.
You can now move on to the Subtypes part of the lesson.
Subtypes (for ArcMap)
Subtypes
In a situation where we have a lot of similar features, roads for example, that we want to easily assign separate attribute values to and symbolize differently, etc., we can designate them as what are called Subtypes. The alternative for managing such data and information would be to create separate feature classes for, in this example, each type of road. This practice can affect the performance and ease of use of the database.
Subtypes can be created for spatial features in a feature class or for objects (records) in a nonspatial, standalone table. Subtypes can be created based on an existing field, or a new field is created to hold the subtype values.
A subtype is defined by a code and a description. The codes are stored in a field in the attribute table and must be either Short or Long Integer values. Each code value is equated to a descriptive category. Sounds a lot like a coded value domain but, as you will see, they are not the same.
In our exercise example, we will be creating road subtypes from integer values that represent six different road type categories.
Follow this link to download the data for this part of the lesson: Subtypes.zip [6]
The zip archive contains two Esri File Geodatabases:
- SubtypesExercise.gdb
- SubtypesProject.gdb
A. Assigning features to subtypes
We are going to place roads in subtype categories according to the values in an existing field that contains integer values that represent six road type categories.
- Open ArcCatalog.
- Navigate to the SubtypesExercise.gdb geodatabase and take note of the two attribute domains: MaintPeriod and RoadSurface.
- Now look into the Roads feature class that resides in the SubtypesExercise.gdb geodatabase. Investigate the attribute data and the properties of the fields. The data in the RoadType field will be the basis for our subtypes, and we will see how attribute domains are involved, too.
As mentioned above, an existing field containing either Long or Short Integer values can be used as the basis for establishing subtypes. The integer values 1 - 6 in the RoadType field represent the following categories of road. Each will become a subtype within our Roads feature class.- 1 - Primary Hwy
- 2 - Secondary Hwy
- 3 - Light Duty
- 4 - Unimproved
- 5 - 4WD
- 6 - Trail
- Let's use those descriptions to establish our subtypes. Open the Feature Class Properties dialog window for the Roads feature class.
- Select the Subtypes tab. Take a look at the aspects involved in defining subtypes. Note the area of the dialog that allows us to set default values for fields and to specify attribute domains. Such settings will be imposed on our existing features and upon new features that we create, providing a measure of automated data integrity control. There are also a Domains button that allows us to review the attribute domains that exist in our geodatabase. This can come in handy when we want to set default values.
- In the Subtype Field dropdown list, select the RoadType field. Recall that it contains the integer values that will become the codes for our subtypes. Also note that the names of the fields in the feature class and any assigned domains are now visible.
- Let us now proceed to provide the Code values and the corresponding Description values for the subtypes. First, replace the 0 in the Code column with a 1, and then change New Subtype to Primary Hwy. Then, using the list of road types above, continue to supply code and description values in the Subtypes area. You can hit the Apply button at any time along the way to preserve your progress of establishing the settings.
- Notice that, by default, the first subtype listed has become the Default Subtype. Let's change that. Assume that we know that a roads improvement project will be beginning that will result in new Light Duty type roads being created. So, let's change the Default Subtype to Light Duty.
- Now, let's spend some time specifying the behavior of each subtype by modifying the settings for each via the Default Values and Domains area. One at a time, we will select each subtype in the Subtypes list and then specify settings for it in the Default Values and Domains area. In order to highlight one of the subtypes in the list, click on the small gray box at the left end of the row. Clicking anywhere in the row of one of the subtypes will select it but won't highlight it and so makes it harder to remember which one we are interacting with.
 Figure 5.10: The Primary Hwy domain highlighted, by clicking on the small box on the left end of the row..
Figure 5.10: The Primary Hwy domain highlighted, by clicking on the small box on the left end of the row.. - Select the Primary Hwy subtype, then, in the Default Values and Domains area, do three things:
- specify the Default Value for the Surface Type field by typing in concrete
- the MaintPeriod range domain was not assigned to the MaintPeriod field (yes, the domain and the field have the same name), so we can do that now -- click in the Domain cell in the MaintPeriod field row, and choose the MaintPeriod domain
- specify a Default Value of 2 (months) for the MaintPeriod field
- For each subtype, proceed to set a default value for the Surface Type field, assign the MaintPeriod range domain to the MaintPeriod field, and set a default value for the MaintPeriod field. Do so according to the following list. Don't forget that you can hit the Apply button at any time during the process to save your progress.
- Primary Hwy | SurfaceType = concrete | MaintPeriod = 2 (already taken care of above)
- Secondary Hwy | SurfaceType = concrete | MaintPeriod = 2
- Light Duty | SurfaceType = asphalt | MaintPeriod = 6
- Unimproved | SurfaceType = cobblestone | MaintPeriod = 8
- 4WD | SurfaceType = gravel | MaintPeriod = 12
- Trail | SurfaceType = grass | MaintPeriod = 12
The image below shows the dialog window with the Trail subtype chosen.
 Figure 5.11: The Subtypes dialog with the Trail subtype chosen. Then the Default Value and Domain are selected for the Surface Type and MaintPeriod fields.
Figure 5.11: The Subtypes dialog with the Trail subtype chosen. Then the Default Value and Domain are selected for the Surface Type and MaintPeriod fields.
- When you are finished, hit the OK button to dismiss the dialog window.
Now, we will go into ArcMap and see what the implementation of the subtypes has put at our disposal. - Open ArcMap and add the Roads feature class to the data frame.
One thing that is an implication of having subtypes assigned will be readily apparent. In the table of contents window, you will see that each subtype is listed along with a distinct symbolization. Go ahead and alter the symbol for each road type if you wish.
 Figure 5.12: The Table of Contents pane in ArcMap, showing the subtypes of the Roads feature class.
Figure 5.12: The Table of Contents pane in ArcMap, showing the subtypes of the Roads feature class. - Now, initiate an edit session. In the Create Features window that opens, notice that each subtype has its own editing template. This serves to reinforce that each subtype is a category unto itself.
 Figure 5.13: The Create Features pane, showing that each subtype of the Roads feature class has an editing template.
Figure 5.13: The Create Features pane, showing that each subtype of the Roads feature class has an editing template. - Let's do something we've done before.
Still in an editing session, open the Roads feature class attribute table.
From the Table Options menu, Select All features. - Now, go to the Editor pull down list on the Editor toolbar and Validate Features.
You should discover that there are 4 violations. What are these based on? In each case, the MaintPeriod value is outside the range specified in the range domain assigned to that field. If you do not get a report of four errors, you may have neglected to assign the MaintPeriod domain to the field of the same name up above.
This reporting of attribute value violations can point to potential problems in the existing data, ones that are less apt to occur in the future now that we have exerted some control over the integrity of data that will be newly created in the context of our subtype settings. - While you are still in the editing session with the attribute table still open, create a new road feature:
- Click on one of the Roads subtypes templates in the Create Features window. Doing so will turn your mouse cursor into the Line construction tool, see beneath the Create Features window.
- Digitize a line feature
- Experiment further if you wish. Save your edits if you wish.
- Close ArcMap, saving your map document if you desire.
So instead of creating separate feature classes for the different road types, we put the road line features into subtypes which gave us the ability to specify unique default values for each new feature of a different road type category, and to assign, or not, certain attribute domains to each category.
B. Project - Subtype Creation
As was mentioned above, subtypes can be created for objects (records) in a nonspatial table. In this homework project, that is what you will do.
Investigate the field structure and attribute data in the Encounters table residing in the SubtypesProject.gdb geodatabase. In addition to the OBJECTID field that is automatically created by the GIS, you will find the following five fields: ID, Encounter, Category, EducationLevel, and BloodAlcohol.
The values of 1 and 2 in the Encounter field represent Distant Encounters and Close Encounters respectively.
The descriptions of the values in the Category field are as follows:
- DE-1 - Nocturnal Light
- DE-2 - Daylight Disc
- DE-3 - Radar-visual
- CE-1 - Light/object in Proximity
- CE-2 - Physical Trace
- CE-3 - Occupant
The encounter data descriptions are based on information I took from the UFO Casebook site [7]: http://www.ufocasebook.com/Hynek.html
The values in the EducationLevel field are the number of years of school attended.
The values in the BloodAlcohol field are blood alcohol content measures. (Wikipedia Blood Alcohol Content Page [8]/ http://en.wikipedia.org/wiki/Blood_alcohol_content)
Here is what I want you to do for this project:
- Create an attribute domain for the three Distant Encounter categories (the DE values)
- Create an attribute domain for the three Close Encounter categories (the CE values)
- Create an attribute domain for the education level data
- Create an attribute domain for the blood alcohol content data
- Create subtypes based on the values in the Encounter field and associate the appropriate attribute domains with each
- Based on the data, choose a default subtype (in spite of the small sample size)
- Based on the data, specify default values for the two encounter subtypes (again, in spite of the small sample size)
When finished, zip your SubtypesProject.gdb geodatabase and submit it to the Project 5 Drop Box.
It can be problematic if the result of zipping your file geodatabase results in an archive name like Sloan_SubtypesProject.gdb.zip -- the embedded .gdb needs to be avoided.
Credit for all screenshots: © Penn State is licensed under CC BY-NC-SA 4.0 [5]
Geodatabase Topology (for ArcMap)
Geodatabase Topology
A geodatabase topology is another construct that is stored within a geodatabase and gives us added control over assessing and maintaining the integrity of our spatial data.
Follow this link to download the data for this part of the lesson: Topology_ArcMap.zip [13]
The zip archive contains the following:
An Esri Personal Geodatabase: geodatabasetopol.mdb
A zip archive: TopologyProject.zip
Controlling spatial data integrity by imposing rules - Geodatabase Topology
A geodatabase topology provides a robust way of defining topological relationships among spatial features. It does so by analyzing coordinate locations of feature vertices, both among features within a feature class and between features in multiple feature classes taking part in the topology. Therefore, it is not only important that all of the feature classes participating in a geodatabase topology be in the same coordinate system, but also that the measurement precision defined for each feature class be the same. To assure that this is the case, all feature classes that take part in a geodatabase topology must reside within what is known as a Feature Dataset. When a feature dataset is created, the coordinate system and precision are defined, and any subsequent feature class that is added to the feature dataset inherits that coordinate system and precision. In the exercise that follows, you will see that the precision is controlled by the Tolerance and Resolution settings. I encourage you to read more about these topics in the Desktop Help when you have time. Search on "topology rules", and then select the "Topology in ArcGIS" topic entry.
A geodatabase topology is governed by topology "rules" that the user specifies, and those rules are based on knowledge of the relationships between and among the features that will be taking part in the topology. So, the onus is on the user to understand the data being created/edited in order that appropriate rules are specified. Rules can be added to and taken away from a topology as long as the data is not part of an active ArcMap editing session.
The manifestation of a geodatabase topology is as a layer in the feature dataset. As such, the topology errors that it contains are symbolized just as are the features in any other map layer in ArcMap. In the Desktop Help, search on "topology rules", and then select the "Geodatabase topology rules and topology error fixes" topic entry. This will take you to a compilation of the types of rules that can be defined along with suggestions for ways to fix violations of each rule and a description of how the errors are symbolized in the map data frame, as Points, Lines, and Areas. If you are inclined to adorn your walls with GIS help guides, you will find a link to a topology rules poster in the opening passage to the Help page I just referred you to. Whether you print it out or not. it offers a bit more in the way of graphic description and examples of the rules.
Once topology rules have been imposed on the data in a feature dataset. errors are discovered by "validating" the topology. Validation can be done on the entire visible extent of the data or on a smaller specified area. The latter technique allows you to just check an area that you have been editing, rather than the entire dataset. This can save time when the entire dataset is large.
As is mentioned above, one needs to be aware of how the features involved in a geodatabase topology relate to each other in order to be able to define appropriate topology rules to govern the creation of spatial data and aid in discovering errors in existing data. In the following exercise, we will be working with the data depicted in the image below, and I will be the arbitrary source of what is known about the relationships among the features in the four feature classes involved. We will be basing our choices of rules on the following:
- the polygons in the FDpolygon_1 feature class must have a single point feature within them
- all of the polygons in the FDpolygon_1 feature class must be within the polygons (there is only one) in the FDpolygon_2 feature class
- the polygons in the FDpolygon_1 feature class must have no gaps between them
- the polygons in the FDpolygon_1 feature class must not overlap
- all of the lines in the FDline feature class must be within the FDpolygon_2 polygons
- all of the lines in the FDline feature class cannot be joined to only one other line feature in the feature class (In topology parlance, the point where only two line segments meet is called a pseudo-node, or -vertex.)
- where lines in the FDline feature class meet, they must be snapped together (The end of a line feature that is not connected to another line feature is said to dangle.)

A. Create and interact with a Geodatabase Topology
- Open ArcCatalog.
- Navigate to your geodatabasetopol.mdb geodatabase.
- Within the geodatabasetopol.mdb geodatabase is a feature dataset named TopolExFeatureDataset, and within it are four feature classes. Verify this, and Preview the data in the feature classes if you wish. You might also check the XY Coordinate System and the Tolerance and the Resolution of the some of the feature classes to see that those settings are indeed the same for each feature class.
- Right-click on the TopolExFeatureDataset name | expand New| select Topology. This will start the New Topology wizard.
Click Next. - Accept the defaults for the name and for the cluster tolerance. Click Next.
- In the next window, click the Select All button to include all of the feature class layers in the geodatabase topology that we are creating.
- Click Next. We now have the option to assign a rank value to each feature class. The lower the number, the higher the rank. A high rank value indicates that positions of the features in that feature class are known more accurately, or that we do not want them to move relative to layers of lower rank during an editing operation. Let's arbitrarily assign the following ranks (though nothing we do in the steps that follow will illustrate the effect of the rankings):
- 1 - FDpolygon_1
- 2 - FDpolygon_2
- 3 - FDline
- 4 - FDpoint
- Click Next. Now based on our knowledge and understanding of how the spatial data in the feature classes are topologically related, we need to specify the rules that help us to ensure that those spatial relationships are maintained. To comply with the relationships among the features that we outlined above, use the Add Rule... button to choose the following rules:
- FDpoint | Must Be Properly Inside | FDpolygon_1
- FDpolygon_1 | Must Be Covered By Feature Class Of | FDpolygon_2
- FDpolygon_1 | Must Not Have Gaps
- FDpolygon_1 | Must Not Overlap
- FDline | Must Be Inside | FDpolygon_2
- FDline | Must Not Have Pseudo Nodes
- FDline | Must Not Have Dangles
- Click Next. You can review the choices just made.
Click Finish.
It will process for a moment and then ask if you would "...like to validate it now?" - Click No. We will validate the topological relationships later in ArcMap.
Now within your TopolExFeatureDataset feature dataset, there will be a geodatabase topology "layer" named TopolExFeatureDataset_Topology. - Open ArcMap, and initiate a new map document.
- You will need the Topology toolbar and the Editor toolbar, so add them to the display if they are not already there.
- Expand the Catalog pane. (If you do not see the tab on the upper-right side, go to the Windows menu and select Catalog.)
Navigate into the TopolExFeatureDataset. - Drag-and-drop the TopolExFeatureDataset_Topology into your data frame.
Click Yes when it asks if you want to add the feature classes that participate in the topology.
The topology layer should display at the top of the Table of Contents list. This is important in order to be able to view the topology errors when they are symbolized. See Figure 5.16, below. - Alter the symbology and rearrange the order of the 4 feature class layers in order to clearly see the features they contain.
Do not label the features yet. - Start an editing session. This will awaken the Topology toolbar.
You can hide the Create Features pane (click the push pin icon). - Take note of the components on the Topology toolbar.
- The icon on the far-right end of the Topology toolbar invokes the Error Inspector. Click it.
The Error Inspector will display beneath the data frame by default. Resize your ArcMap window as needed in order to see it.
 Figure 5.15: The Error Inspector pane.
Figure 5.15: The Error Inspector pane. - Recall that when we created the geodatabase topology in ArcCatalog, we chose not to validate the topological relationships at that time. Let's do that now. First, be certain you can view all of the features in the map display area. You literally need to be able to see the features -- it isn't enough that they are in the data frame, if they are in the data frame but covered by the Error Inspector pane for example, they will not be validated.
The Validate Topology in Current Extent tool is the third icon from the right end of the Topology toolbar.
Click it.
Several features in the colors indicated in the Table of Contents pane for the topology layer should be visible. We will spend the next several steps investigating what they tell us.
(The image below also shows the results of the feature labeling we will do in the next step.)
 Figure 5.16: The map document, showing the TopolExFeatureDataset_Topology geodatabase topology added to the data frame, along with the layers that take part in the geodatabase topology. The image also shows the labeling of the features.
Figure 5.16: The map document, showing the TopolExFeatureDataset_Topology geodatabase topology added to the data frame, along with the layers that take part in the geodatabase topology. The image also shows the labeling of the features. - Before we proceed, let's label the features in the data frame with the values in the OBJECTID field of each feature class. For each layer, bring up the Layer Properties window | select the Labels tab | change the Label Field to OBJECTID | click OK. Then right-click on the layer name in the table of contents and select Label Features.
- Keep in mind what you read above, at the beginning of this section, in regard to what are the desired spatial relationships of the features in the dataset we are working with.
Expand the Show: picklist in the Error Inspector, and choose FDline - Must Not Have Pseudo Nodes, and then click the Search Now button. NOTE: It is still important that all of the features still be visible in the data frame.
Two entries will appear in the Error Inspector table. - Click on the row in the Error Inspector that holds the first error entry, where Feature 1 is 10 and Feature 2 is 16. The Feature # is the value of the OBJECTID field. This is why I had you label the features with the values in the OBJECTID field.
This type of error is represented by a Point Error symbol, the pink square. When you click the row in the Error Inspector, the pink square that separates line features 10 and 16 will turn black, thus indicating the location of the instance that violates this particular topological rule, each line feature in the FDline feature class should share an end point with at least two other lines. The highlighted Point Error indicates a situation where only two line features are sharing an endpoint. - If you right-click on the line entry in the Error Inspector, it will bring up a list (see Figure 5.17 below) from which you can choose to, among several things, Merge or Merge To Largest. These are two choices in the context of this particular type of error for fixing the problem. The Merge choice gives you an option to choose one of the two line features. The implication is that the attributes associated with the chosen line will be those retained for the new single line feature that is a result of the Merge.
Go ahead and experiment with the choices in the list. You can always Undo any change you make. (Ctrl-Z, or Edit menu | Undo... or use the Undo... tool icon.) Figure 5.17: The menu that comes up when you right-click on an entry of the Error Inspector pane.
Figure 5.17: The menu that comes up when you right-click on an entry of the Error Inspector pane. - There is a second violation of the Must Not Have Pseudo Nodes error. Highlight it via the Error Inspector. You'll see that it is where line features 8, 14, and 15 are supposed to meet. If you zoom in far enough on that intersection, you will see that line 8 is not snapped at the intersection of lines 14 and 15.
- It turns out that one of our other rules would have also highlighted an error in that same area. Do you know which one? Expand the Show: picklist in the Error Inspector, and choose FDline - Must Not Have Dangles, and then click the Search Now button.
- In the list of errors, click the first row where Feature 1 is equal to 8 (it ought to be third from the bottom). That should also highlight a vertex in the vicinity of where line feature 8 is supposed to be snapped at the intersection of lines 14 and 15. Which vertex is highlighted? It is the end vertex of the 8 line feature.
The list of Must Not Have Dangles errors contains 10 entries. It is important to realize that not all dangling line feature endpoints are actually errors. It is acceptable to have dead end streets for example. - It is also important to realize that the Must Not Have Dangles rule only pertains to features in a single layer. If you click through the list of ten dangle errors, you will see that three of the entries on the list are where line features 7, 8, and 9 meet the corners of polygon 11 (the FDpolygon_2 feature). If you do some investigating, you will find that the end of line 7 is indeed snapped to the corner vertex of polygon 11. Even so, the geodatabase topology still flags it as a possible error. To prove to yourself that line 7 is snapped to the polygon boundary, you may need to invoke a Map Topology. Do you recall how from having taken Geography 484?
- Now, let's look at the FDpolygon_1 - Must Not Have Gaps error results.
Select it from the Show: picklist in the Error Inspector.
Then hit the Search Now button. You should see two results listed in the Error Inspector represented by the Line Error symbol. - One of the Error Inspecctor entries, when chosen from the list, will show the result depicted in the image below (Figure 5.18).
Click on the two entries until you find it.
Part of the description of this topology rule includes the following: "An error will always exist on the perimeter of the surface. You can either ignore this error or mark it as an exception."
 Figure 5.18: The view of the FDpolygon_1 data after you chose the desired Must Not Have Gaps entry in the Error Inspector.
Figure 5.18: The view of the FDpolygon_1 data after you chose the desired Must Not Have Gaps entry in the Error Inspector. - Let's mark this as an exception.
Right-click on the error entry in the Error Inspector table and choose Mark As Exception. The pink lines marking the perimeter of each of the polygons will disappear and the error will disappear from the Errors list.
Note the Exceptions check box. You can search for things that you have marked as such if need be. - Highlight the remaining error on the list, take note of where it is (between polygons 2 and 5), and in the table of contents window, un-check the box controlling the display of the topology layer. This will prevent the topology features from hiding what we are looking for. When you zoom in far enough, you should discover a gap between FDpolygon_1 polygons 2 and 5. Someone did not do a good job of making sure the FDpolygon_1 features shared boundaries.
Let's stick with the FDpolygon_1 polygon layer and perform an edit. While we are at it, we will learn how to highlight areas in our data that have been modified/edited. These "dirty areas," as they are referred to, let us know that we should validate the topology again. - Zoom back out to Full Extent.
In the Error Inspector, show the FDpolygon_1 - Must Not Overlap error, and hit the Search Now button. There should be two errors. We are going to focus on the error involving polygons 2 and 3. - Turn off the display of the topology layer and zoom in on the location of the overlap error between polygons 2 and 3 until you have a good view of the overlap. You could elect to change the display of the layer to "Hollow" in order to see the overlap more definitely.
- Now, before we attempt to correct the error, go to the Layer Properties of the TopolExFeatureDataset_Topology layer | select the Symbology tab | check the box for Dirty Areas | click OK. A new "Dirty Areas" hatch symbol will appear in the table of contents under the topology layer.
- Let's rectify the overlap using the canned error correction choice provided by the Error Inspector. Right-click on the error in the Error Inspector and select Merge from the menu.
- In the Merge window that opens, click on each of the two entries. Doing so will cause the polygon that the overlap area will be merged with to be flicker-highlighted.
- Choose the first of the two -- the PLY12(FDpolygon_1) entry, and then click the OK button.
- If you still have the display of the TopolExFeatureDataset_Topology layer un-checked, check the box now. Polygon 3 should be highlighted in the hatch pattern, indicating that it is a dirty area -- that a change has been made since the topology rules were last validated.
- Zoom to full extent. We are going to use the Validate Topology In Specified Area tool
 (fourth from the end on the Topology toolbar) to see if the correction we made to the overlap is no longer considered an error. Select that tool and click-drag a rectangle that will encompass the hatched area. When you let off the mouse button, the hatched area should disappear, indicating that the error has been correctly dealt with as far as our topology rules are concerned.
(fourth from the end on the Topology toolbar) to see if the correction we made to the overlap is no longer considered an error. Select that tool and click-drag a rectangle that will encompass the hatched area. When you let off the mouse button, the hatched area should disappear, indicating that the error has been correctly dealt with as far as our topology rules are concerned.
To prove this to yourself, you can hit the Search Now button and see how many overlap errors are found. There should be only one left. - You should save your edits now.
- Deliverable- I want to see that you were able to perform the correction we just went though, so zip up your geodatabasetopol.mdb geodatabase and upload it to the Project 5 Drop Box.
You should be getting a feel for how to interact with the Error Inspector.
Go ahead and spend some time investigating the other rules infractions to see if you can determine the reasons for the other error symbols that you see on the map.
- Why is there a Point Error at the bottom-left corner of the FDpolygon_1 polygon 5 feature (point 3)?
- Why is line 9 highlighted?
- etc.
If you want, attempt to correct some of the other errors. Not all of them (like the gap we found between the two polygons) have canned fixes via the Error Inspector. So if you are pining away for a chance to do some editing, be my guest.
I leave it up to you to choose whether or not to save the map document, and any edits you make.
B. Using topology editing tools with shared polygon boundaries
With a geodatabase topology in place, there are certain tools at your disposal that enable you to maintain topological relationships when you make edits to spatial data. Here, we contrast editing a shared polygon boundary with and without having a geodatabase topology set up. It is important to realize that the "shared" boundary between two polygons actually is a duplicate set of line segments, each polygon boundary exists as complete and independent from the adjacent polygon. So when a shared boundary needs to be edited, one must actually edit the boundaries of two polygons.
- First we will look at the case where we have no topology imposed on the data, and we attempt to edit a shared polygon boundary with the Edit Vertices tool . The images below illustrate what happens. Because only one feature can be selected when editing with the Edit Vertices tool, only one instance of the extent of the shared boundary can be edited at a time. The images depict a simple case, but think of a situation where three or four polygons share a common corner vertex.
 Figure 5.19: Two polygon features in a geodatabase feature class that share a boundary.
Figure 5.19: Two polygon features in a geodatabase feature class that share a boundary. Figure 5.20: The result of editing/moving one vertex when no geodatabase topology is in place.
Figure 5.20: The result of editing/moving one vertex when no geodatabase topology is in place. - With a geodatabase topology in place, one can first use the Topology Edit Tool
 to select the length of the shared boundary. Then, using the Modify Edge tool
to select the length of the shared boundary. Then, using the Modify Edge tool  (which when invoked causes the vertices to display), a shared vertex can be selected and moved, editing both polygon boundaries at the same time. Holding down the Shift key when selecting vertices allows you to select more than one.
(which when invoked causes the vertices to display), a shared vertex can be selected and moved, editing both polygon boundaries at the same time. Holding down the Shift key when selecting vertices allows you to select more than one.
 Figure 5.21: With a geodatabase topology in place, and the shared boundary selected using the Topology Edit Tool.
Figure 5.21: With a geodatabase topology in place, and the shared boundary selected using the Topology Edit Tool. Figure 5.22: The result of editing/moving two shared vertices when a geodatabase topology is in place.
Figure 5.22: The result of editing/moving two shared vertices when a geodatabase topology is in place.
C. Project - Given a single feature class in a geodatabase, set up a geodatabase topology and deal with a single class of error
Because this is not a course in inputting and editing spatial and attribute data, we are choosing to focus on what needs to be done to prepare to implement a geodatabase topology. There will be some errors in spatial data to repair, but it involves going over ground already covered in section A of the lesson.
Unzip the TopologyProject.zip archive. The archive contains a folder named TopologyProject. Within that folder is a map document (TopologyProject.mxd file), a geodatabase (TopologyProject.gdb) and a georeferenced image of a map (with ancillary files). When you unzip the archive, keep the folder and its contents intact. The map document is set to maintain relative paths to the data that it points to, so after you have extracted the folder and you navigate into it and double-click on the TopologyProject.mxd, the map image and the single feature class contained in the geodatabase should be present in the resulting ArcMap session.
The BuildingFootprints feature class contains some instances of polygon overlap that need to be repaired.
In order for you to accomplish finding and repairing the errors in the BuildingFootprints feature class, you are going to have to create and employ a geodatabase topology. You know from section A how to create a geodatabase topology, and you know that in order to do so, the data in question has to reside within a feature dataset. What we did not explicitly go over in the lesson was how to (1) create a feature dataset, and (2) how to get existing data, in this case the feature class contained in the TopologyProject.gdb, into a feature dataset that we create. But that's what I want you to do. Given that Geography 484 or comparable experience was the prerequisite for taking this course, you should be able to do it.
Once you have accomplished that, proceed to find and correct the overlapping building footprint polygons. All of the offending features will be in the area covered by the included georeferenced map image. You can use it as a reference to make sure you are performing the corrections to the polygons correctly.
When you finish, zip up your version of the TopologyProject.gdb and upload it to the Lesson 5 Drop Box.
Credit for all screenshots: © Penn State is licensed under CC BY-NC-SA 4.0 [5]
Project 5: Esri Geodatabase Behaviors
Project 5: Esri Geodatabase Behaviors
A. Deliverables
This project is one week in length. Please refer to the Canvas Calendar for the due date.
The various Project deliverables were described along the way throughout the lesson. Below is a list summarizing what you need to submit.
- Attribute Domains - Upload your version of the AttributeDomainsProject.gdb geodatabase, and the screen capture showing the results of discovering the errors, both zipped into your last name_Lesson5_Domains.zip
- Subtypes - Upload your SubtypesProject.gdb geodatabase, zipped and named appropriately.
- Geodatabase Topology - (1) Upload your version of the geodatabasetopol.gdb geodatabase, and (2) your version of the TopologyProject.gdb, zipped and named appropriately. (I do not need your map document or any of the image files.)
- Complete the Lesson 5 quiz.