Random Forest Classification
 Read It: Random Forest Classification
Read It: Random Forest Classification
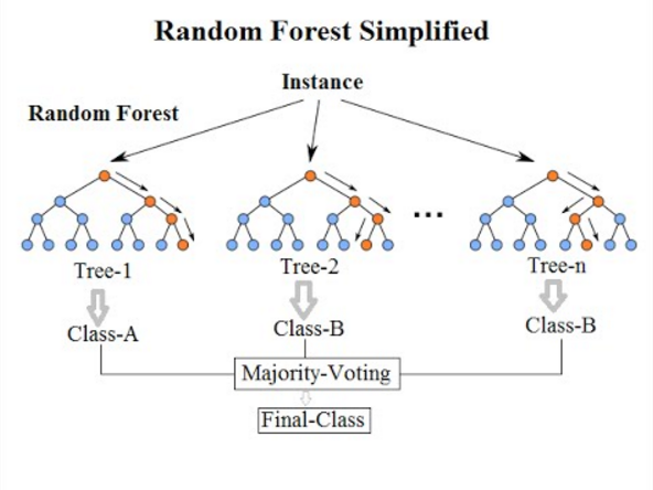
Within the random forest model, users often specify the number of trees to be built. Each of these trees use a different bootstrapped sample of data and a different sample of explanatory variables, creating many different trees. The final model outcome is then the aggregation of these trees. This aggregation can happen in two different ways, depending on the model goal. If, for example, the goal is classification of categorical variables, the aggregation is based on a majority-rule voting scheme, shown in the figure below. That is, the class of a given data point is selected based on whichever class was most common across all the trees. For example, if a data point is classified as "green" in 60% of the trees, "red" in 30% of the trees, and "blue" in 10% of the trees, the majority-rule voting scheme will result in a final classification of "green".
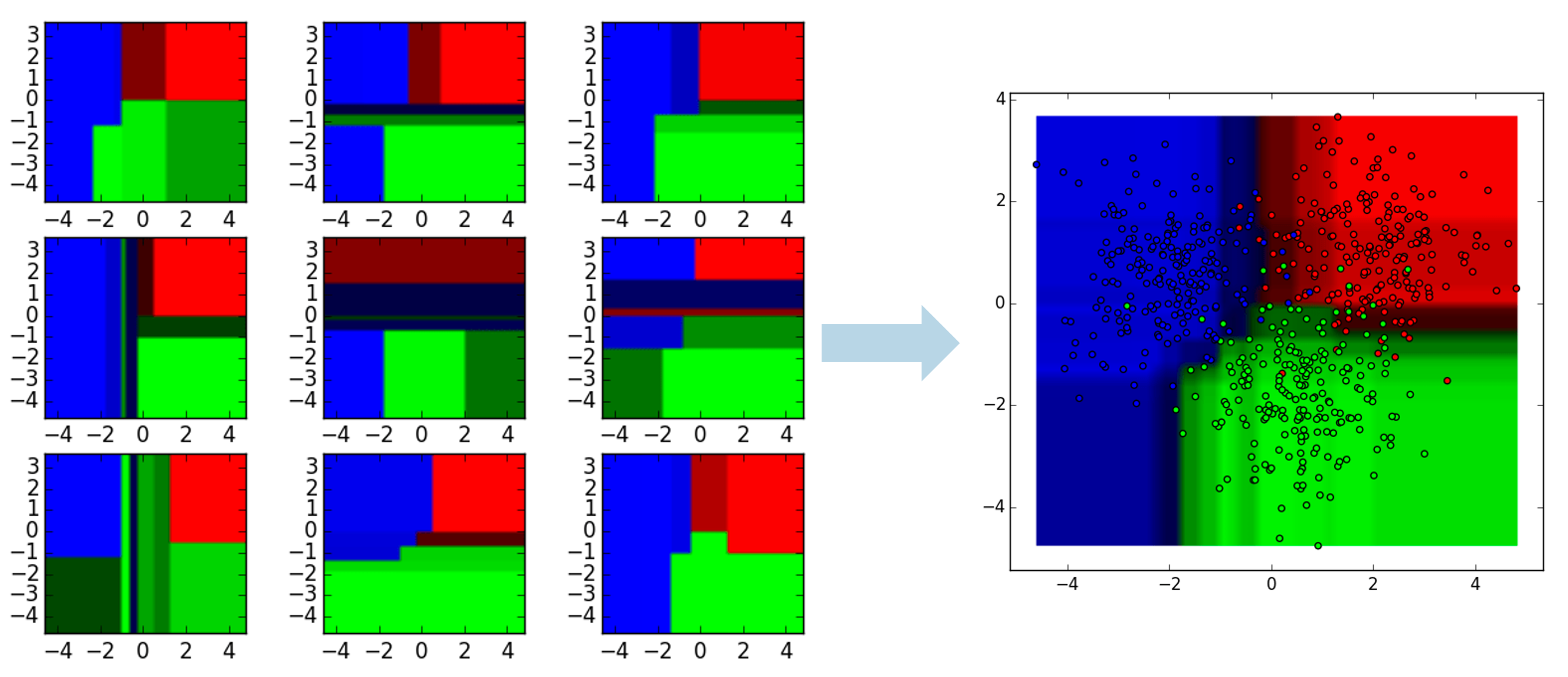
An example of this aggregation is shown below. Notice how each classification looks slightly different, but the final aggregation shows the combination of all nine classification results.
Below, we demonstrate how to apply a random forest classification model in Python. We will include four key steps:
- Split the data into training and test/validation sets (80/20 is a common split)
- Specify the model parameters (e.g., number of trees, maximum depth of any given tree, etc.)
- Fit the model to the training data set
- Evaluate predictive accuracy using the test/validation data set
 Watch It: Video - Random Forest Classification (12:58 minutes)
Watch It: Video - Random Forest Classification (12:58 minutes)
Hello. Welcome to the start of the video series on random forests. Now, random forests, as you've learned in this lesson, are a great tool for making predictions. And so, essentially they build a lot of individual decision trees and then merge them all together to get a more stable and often more accurate prediction. Now, within this lesson, we're going to start with classification using random forests and then we're going to get into regression with random forests. Which is one of the nice things about this technique is that you can use it for both classification of groups and regression of numbers. So, with that let's go ahead and dive in.
So, we're here in Google collab and we've got some libraries that we need to save. And so, one of the things that you might notice depending on when you start to do random Forest, is that this tensorflow decision forests is a new library for us. And sometimes depending on what your run time is like, you need to first install it. And so, right now you can see that there's got this squiggly line underneath the library which is telling me that there's something wrong, and if I run this command, block of commands that are loading all my libraries, we can see that I get this error no module named tensor decision forests. And so, if you get that error, all you need to do is run this pip install line to install the package onto Google collab and the reason this happens is because tensorflow decision forests is not a standard package. So we need to install it and essentially it's going to run through all of these different lines but at the end it tells us that it successfully installed the library. And so, now I can go through and import all of the libraries.
So, once our libraries are installed and our Google Drive is mounted, we can get into the actual problems. And so, what we are going to do is try to predict the type of house based off of energy consumption and sort of the situation that you can imagine yourself in, you're working at a utility. Who wants to better understand their customer base? They want to try to figure out which housing unit types exist without needing to go to those specific houses. And so, we are going to try to predict this housing unit type based off of features variables that you can easily see from bills.
So, to give some further background, our how our data set, we would be predicting type huq, and there are five different categories. Mobile home, single family detached, single family attached, small apartment, large apartment. And I want to point out that it's really convenient that our data is already coded numerically, because that's something that is a requirement for the random Forest Package. And so, if you were to be running this with a separate data set that maybe was labeled a b c d, you would need to convert those into numbers in order to give this model to run correctly.
But before we get started I've already set up some data sets. So we are only looking at the energy use data. And so, we've got our response variable and I've selected several predictors or explanatory variables that can be used to maybe predict what housing type is, based off of data that is available in a billing data set, for example. So there's energy or electricity, Natural Gas, Energy Assistance, liquid propane, fuel oil, wood cords, and then wood pellets. So with that let's go ahead and get into actually modeling. So the first step that we need to do is split our data into training and test. And so, I'm actually going to simultaneously create both of these variables using the train comma test. So this will create one variable called train and another called test and the actual command we are using is train test split. we give it our data set and then we give it our test size. and so, because we want to split it into 80 percent training 20 percent test, I specify 0.2 as my test size this is something that you could change in your own work if you thought maybe you would get a better fit with a smaller or larger amount of test data. So let's go ahead and look at what this training data set looks like. So you can see that we've got these random numbers because it's shuffled the data and then randomly pulled out 80 percent and we've got our response variable in all of our explanatory variables. But before we can use this in our tensorflow model we need to convert the data into a tensorflow object. So I'm going to create a new data set called train DS and the command we're using is tfdf. S, this is from that tensorflow decision forests, which I've nicknamed tfdf.
So, we say tfdf dot keras dot pd underscore dataframe underscore 2 underscore TF underscore data set. And then we give it what our data frame was called. So train and a very important step we tell it which data set to program as the label or response variable. So type HQ. I'm going to copy that and change some words because we need to do it again with our test data set but we don't need to change the label. And so, then if we look at what this looks like.
It's essentially just an object. So it's not actually a data frame or even a dictionary like we are used to. It is an object that is stored in memory space but the computer will know what to do with it when we get into the model definition. And so, that's step two. So now we have our data set. So now we need to define the model and we've got a few parameters that we're going to define here. Tell the model how to actually formulate this random Forest. I'm just going to call my model, model and we're using that tfdf Library again dot karis dot random Forest model.
And this is where we actually tell it what we're actually what we want the model to look like. So the first thing we want to do is say compute oob which stands for out of bag variable importances and we want to set that to true. Ad so, this will tell the computer to calculate the importance for each of our predictors or explanatory variables, which we'll use later when we do interpretation. Then we want to set the number of trees/ I'm going to set it to 50. It defaults to 300. The smaller number of trees you use the longer the model will take to run. So I'm going to use a lower number for the sake of the video.
And then I'm going to set a max depth of 12. So this is, sort of, how complex you want your model to be. Larger depths means more complexity but also a greater chance of overfitting the data. So we can see that it's told us where it's actually storing this model. If we print it, we can see that it's once again just one of these weird objects. We can't actually see anything yet. but the computer knows where it is and knows how to use it. Then the last part of the model definition is an optional chance to specify the metrics. So we are going to put specifically specify accuracy which is defined here. So the way we're going to measure how good our model is, is by how accurate it is. The total number of correct predictions divided by the total number of predictions.
And so, at this point we've defined the model there's but we haven't added any data in here. So if you look at this, there's nothing to suggest that this model is connected to our training data set yet. And so, that is what we do when we fit the model in step three. So we say model dot fit train underscore DS using that tensorflow object, and as we run this, we can see it's going to print out a few data sets for us. So it sort of tells us what it's doing as it goes through. It tells us that it took 5.6 seconds to read in the training data set but then it trained it in 0.78 seconds. so less than a second of training. It's given us some warnings but we don't really need to worry about that because we're not interested in this autograph command. And then we can continue on because it's told us that it has done this correctly. And so, then the final step here. So we've now defined our model and fit it to the training data but we want to see how accurate it is. So we're going to compute the accuracy with the test set. So in this case this is the 20 of data that we held out in step one. So I'm going to call it evaluation and we say model which is what I named my model evaluate and, in this case, we give it a test object and we're going to say return dict equals true to return it as a dictionary. okay.
So, I accidentally double-clicked and interrupted but here we can see that it's now printed out our accuracy for our model. So our model has an accuracy of 0.71 which means that 71 percent of our data points were accurately classified within the test set. And so, we'll stop here for this video and then in the next one we'll get into how we can interpret the results of this classification model.
 Try It: GOOGLE COLAB
Try It: GOOGLE COLAB
- Click the Google Colab file used in the video here.
- Go to the Colab file and click "File" then "Save a copy in Drive", this will create a new Colab file that you can edit in your own Google Drive account.
- Once you have it saved in your Drive, try to edit the following code to apply a random forest classification model to the RECS dataset:
Note: You must be logged into your PSU Google Workspace in order to access the file.
# load the dataset recs = pd.read_csv(...) # split the data into 20/80 test/training sets train, test = train_test_split(...) # reformat the data to a tensorflow dataset train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train, label = ...) test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test, label = ...) # create the random forest model model = tfdf.keras.RandomForestModel(...) model.compile(metrics = ['Accuracy']) # fit model with training data model.fit(...) # evaluate model accuracy using test data evaluation = model.evaluate(...) evaluation
Once you have implemented this code on your own, come back to this page to test your knowledge.
 Assess It: Check Your Knowledge
Assess It: Check Your Knowledge