In this homework assignment, we want you to practice working with pandas and the other Python packages introduced in this lesson some more, and you are supposed to submit your solution as a nice-looking script.
The situation is the following: You have been hired by a company active in the northeast of the United States to analyze and produce different forms of summaries for the traveling activities of their traveling salespersons. Unfortunately, the way the company has been keeping track of the related information leaves a lot to be desired. The information is spread out over numerous .csv files. Please download the .zip file containing all (imaginary) data you need for this assignment and extract it to a new folder. Then open the files in a text editor and read the explanations below.
Explanation of the files:
File employees.csv: Most data files of the company do not use the names of their salespersons directly but instead refer to them through an employee ID. This file maps employee name to employee ID number. It has two columns, the first contains the full names in the format first name, last name and the second contains the ID number. The double quotes around the names are needed in the csv file to signal that this is the content of a single cell containing a comma rather than two cells separated by a comma.
"Smith, Richard",1234421 "Moore, Lisa",1231233 "Jones, Frank",2132222 "Brown, Justine",2132225 "Samulson, Roger",3981232 "Madison, Margaret",1876541
Files travel_???.csv: each of these files describes a single trip by a salesperson. The number in the file name is not the employee ID but a trip number. There are 75 such files with numbers from 1001 to 1075. Each file contains just a single row; here is the content of one of the files, the one named travel_1001.csv:
2132222,2016-01-07 16:00:00,2016-01-26 12:00:00,Cleveland;Bangor;Erie;Philadelphia;New York;Albany;Cleveland;Syracuse
The four columns (separated by comma) have the following content:
- the ID of the employee who did this trip (here: 2132222),
- the start date and time of the trip (here: 2016-01-07 16:00:00),
- the end date and time of the trip (here: 2016-01-26 12:00:00),
- and the route consisting of the names of the cities visited on the trip as a string separated by semi-colons (here: Cleveland;Bangor;Erie;Philadelphia;New York;Albany;Cleveland;Syracuse). Please note that the entire list of cities visited is just a single column in the csv file!
There are a few more files in the folder. They are actually empty but you are not allowed to delete these from the folder. This is to make sure that you have to be as specific as possible when using regular expressions for file names in your solution.
Your Task
The Python code you are supposed to write should take a list of employee names (e.g., ['Jones, Frank', 'Brown, Justine', 'Samulson, Roger'] )
It should then produce a new .csv file that lists the trips made by employees from the given employee name list with all information from the respective travel_???.csv files as well as the name of the employee. The rows should be ordered by employee name. The figure below shows the exemplary content of this output file.
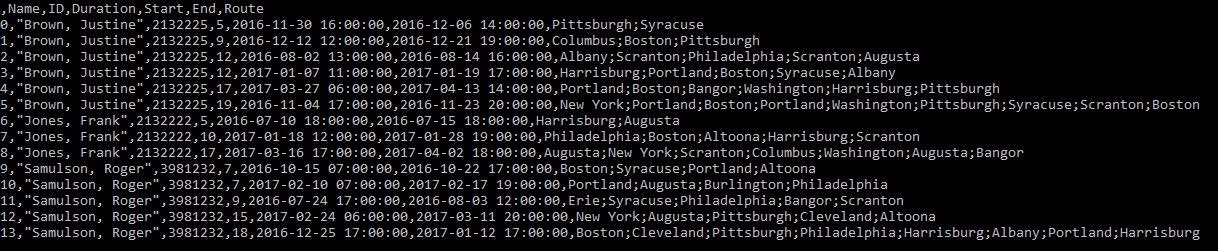
Steps in Detail
Your script should roughly follow the steps below; in particular you should use the APIs mentioned for performing each of the steps:
- The input variables defined at the beginning of your code should include
- the list of employee names to include in the output
- the folder that contains the input files
- the name of the output csv file
- Use pandas to read the data from employees.csv into a data frame (see Hint 1).
- Use pandas to create a single data frame with the content from all 75 travel_???.csv files. The content from each file should form a row in the new data frame (see Hints 1 and 2). Use regular expression and the functions from the re package for this step to only include files that start with "travel_", followed by a number, and ending in ".csv".
- Use pandas operations to join the two data frames from steps (2) and (3) using the employee ID as key. Derive from this combined data frame a new data frame with only those rows that contain trips of employees from the input name list
- Write the data frame produced in the previous step to a new csv file using the specified output file name from (1) (see Hint 1 and image of example csv output file above).
Hint 1:
Pandas provides functions for reading and writing csv files (and quite a few other file formats). They are called read_csv(...) and to_csv(...). See this Pandas documentation site for more information(link is external)
import pandas as pd
import datetime
df = pd.read_csv(r'C:\489\test.csv', sep=",", header=None)
Hint 2:
The pandas concat(…)(link is external) function can be used to combine several data frames with the same columns stored in a list to form a single data frame. This can be a good approach for this step. Let's say you have the individual data frames stored in a list variable called dataframes. You'd then simply call concat like this:
combinedDataFrame = pd.concat(dataframes)
This means your main task will be to create the list of pandas data frames, one for each travel_???.csv file before calling concat(...). For this, you will first need to use a regular expression to filter the list of all files in the input folder you get from calling os.listdir(inputFolder) to only the travel_???.csv files and then use read_csv(...) as described under Hint 1 to create a pandas DataFrame object from the csv file and add this to the data frame list.
Write-up
Produce a 400-word write-up on how the assignment went for you; reflect on and briefly discuss the issues and challenges you encountered and what you learned from the assignment.
Deliverable
Submit a single .zip file to the corresponding drop box on Canvas; the zip file should contain:
- Your script file
- Your 400-word write-up