Normal Distribution and Z-Scores
 Read It: The Normal Distribution
Read It: The Normal Distribution
The normal distribution is a common distribution of data, which is frequently plotted as a bell-shaped curve. In this curve, the mean is plotted at the center or peak of the bell with the sides of the curve being completely symmetrical. The width of this curve is determined by the standard deviation of the data. In this sense, to plot a normal distribution, you need only two parameters: the mean and the standard deviation. We define, or denote, the normal distribution by using the capital letter N, followed by the mean, μ, and the standard deviation, σ. You can calculate the normal distribution for any any dataset using the probability distribution function, shown below.
The probability density function (pdf) of the Normal distribution is:
with parameters = mean and = standard deviation
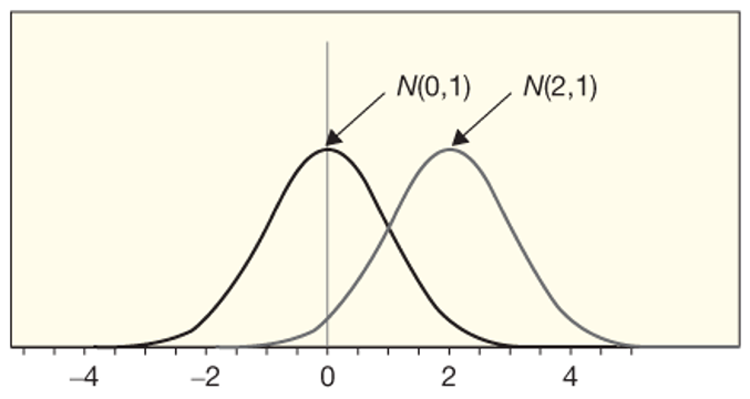
The standardized version of normal distribution has a mean of 0 and a standard deviation of 1, as shown in the figure below. Note that by changing the mean from 0 to 2, the plot shifts to the right, but maintains the same width since we did not change the standard deviation.
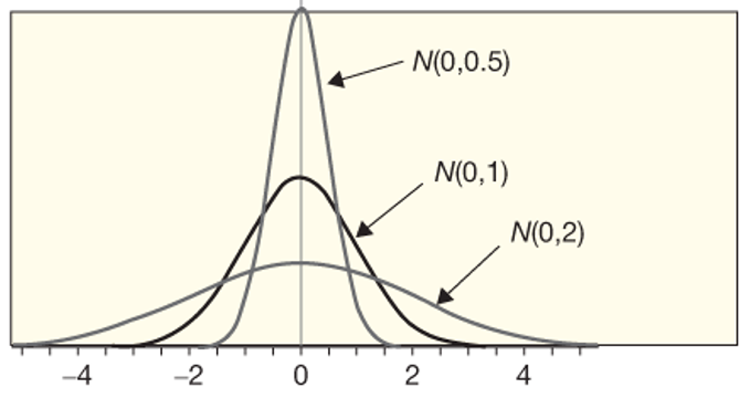
In the figure below, you can see as the standard deviation goes from 0.5 to 2, the curves get wider, but the plot remains centered at 0 since we do not change the mean at all.
Read It: Z-Scores
Often, when working with traditional statistical inference, you will need to calculate a quantity known as the "z-score". The z-score is a means of standardizing any data to fit with the standard normal distribution (e.g., N(0,1)). This calculation is performed using the equation below. Essentially, you subtract the mean from your data and divide by the standard deviation.
Traditionally, this z-score is used to find confidence intervals and test hypotheses using the central limit theorem. However, it can also be used to detect outliers: a z-score > 3 is generally considered to be an outlier.
 Watch It: Fitting Normal Distributions - (7:45 minutes)
Watch It: Fitting Normal Distributions - (7:45 minutes)
 Try It: Google Colab
Try It: Google Colab
- Click the Google Colab file used in the video here(link is external).
- Go to the Colab file and click "File" then "Save a copy in Drive", this will create a new Colab file that you can edit in your own Google Drive account.
- Once you have it saved in your Drive, try to edit the following code to fit a normal distribution to some data:
Note: You must be logged into your PSU Google Workspace in order to access the file.
1 2 3 4 5 6 7 8 9 10 | meandist = ...SEdist = ...phatdf['x_pdf'] = np.linspace(...) phatdf['y_pdf'] = stats.norm.pdf(..., loc = ..., scale = ...)(ggplot(...) + geom_dotplot(aes(...), dotsize = 0.25) + geom_line(aes(...), color = 'red', size = 1)) |
Once you have implemented this code on your own, come back to this page to test your knowledge.
 Assess It: Check Your Knowledge
Assess It: Check Your Knowledge