Click here for a transcript.
So now we're going to get into the actual bootstrapping. So we're going to start with a very brief review of what we went, how we got the original four samples and that original sampling distribution in the previous videos. And then we're going to leverage a for loop to create a thousand samples that are of equal size to our original samples.
So here we are in Google lab we've got our libraries that we're going to be using in this script, and we've got the same code that we went over in the previous video. So we've got our four samples, 10 dice rolls each, and we found the sample means of each one. And this is a sampling distribution it, but it's quite small. And so it's hard to say how we could make any statistical inference because it's so small. Generally, we want something that is sufficiently large enough. And so one way that we can improve our statistical standing is to get a bootstrapped distribution. And so in order to do this, we will essentially collect a thousand samples by resampling from our existing data, and we'll use that to ultimately make some inferences through confidence intervals. And so I've laid out our pseudo code here. We're going to start with initializing all of the variables, then we're going to create loops. We're going to use a function called MP random Choice, and then we're going to move the counter forward and complete the loops.
So the first thing that we do is initialize the variables. So we can say step one. So there are a few key variables that we have to initialize. The first is capital N and so this is the number of bootstrap iterations. Then we need to do lowercase n. and this is our sample size. So above in the previous lectures we had four samples, but we had 10 rolls in each sample. So we'll say N little n equals 10. And then we're going to create an empty data frame, which we call boot DF. And so this data frame, again we're going to use that dictionary within a data frame that we've used before. We're going to initialize one column called sample. And for now it's going to be empty, so we use NP nan times and capital N by little n. So this will give us n by n so 10,000 rows of not a number. And then we want another column called outcome, in which we do the same thing. So we're going to fill it with n by n not a number and then finally we will have a type column and do the same. So if we just print, what that looks like do the first five rows. We can see that we've got sample outcome and type all empty.
So then we need to get into the actual loop which is step two, so I'll and do a new code step two. And so it follows our basic syntax that we went over in the previous video. So we say 4 I in range n. and so unlike the previous video I'm just going to give it a single value, and it will assume that 0 is our first number. So if you just give it a single value, it'll assume that's the end. So we'll do a thousand iterations. And so that has started the loop. So now our next step, step three, is to extract a random sample. And so, to do this, we need to first develop some counters within our for loop. So we're going to have one counter called low I, which is just little n times I. And then we're going to have high I which is the low I plus n minus 1. And so what these are going to do is it's going to allow us to move through our boot DF database data frame. And so the first iteration of I will take care of 0 to 10. The second one will take care of 11 to 20 and so forth. So these are our indices, and then we can start to actually build up this empty data frame. And so we can say boot bf dot loc. So this will allow us to locate based off of a column, so we can say from low I to high I. so these are our indexes, and we've got a colon there to say from this to that. In the outcome columns, we say MP dot random dot choice. We give it our original data frame, which we called data DF. So I'll just copy and paste that. So the first part of MP dot random choice tells us what we're actually drawing from, or drawing from the outcome column of data DF. the second option tells it what size we're drawing. We're going to go with little n which is our sample size.
And then the third option, we say replace equals true. And this is a key option when you're doing bootstrapping. You want to make sure you're always replacing it. This means that there might be a case where you have a bunch of the same numbers that have been drawn in a row that are all the same, but that is the purpose of doing this bootstrapping. We don't want to end up with only one option to draw from because we haven't replaced the marbles in the bag, for example. We want to draw a marble, record the color, and replace it. So this is a really critical component of the bootstrapping code. So that actually extracts the random sample. The next case was moving the counter. And so in this case we're going to say boot df dot loc. Again from low I to high I. but in this case we want to do sample, and we're going to say boot and plus SDR I plus one. And so what this will do is it will essentially create a label for us that tells us which bootstrap iteration we're on. And then we have step five, which is tracking the type of sample.
And so again from low I to high I. In this case we want the type column, and we're just going to call it bootstrap. And for now this will all be all bootstrap. But if we were also tracking our truth, for example, we could change that type so that we can identify it later. And then step six is to end the loop. So I've backspaced so that I'm now realigned with the very edge of the pane. And then I will print the first five rows of bootstrap DF, so that we can see what it looks like. And so there is an error. It looks like I've got the wrong name. Yes, so we need this to be a little outcome. So one of those things that python is very particular with the cases that you have in the capitalization and where it occurs. So pretty common error there. But now we can see we've run through it, we've got our sample, we've got the random draw, and then we've got the type here. So now we've got the bootstrap samples but in order to develop the bootstrapping sampling distribution, we need to make sure that we do the mean of this bootstrap sample. So we'll get into that in the next video.
 Read It: Bootstrapping
Read It: Bootstrapping 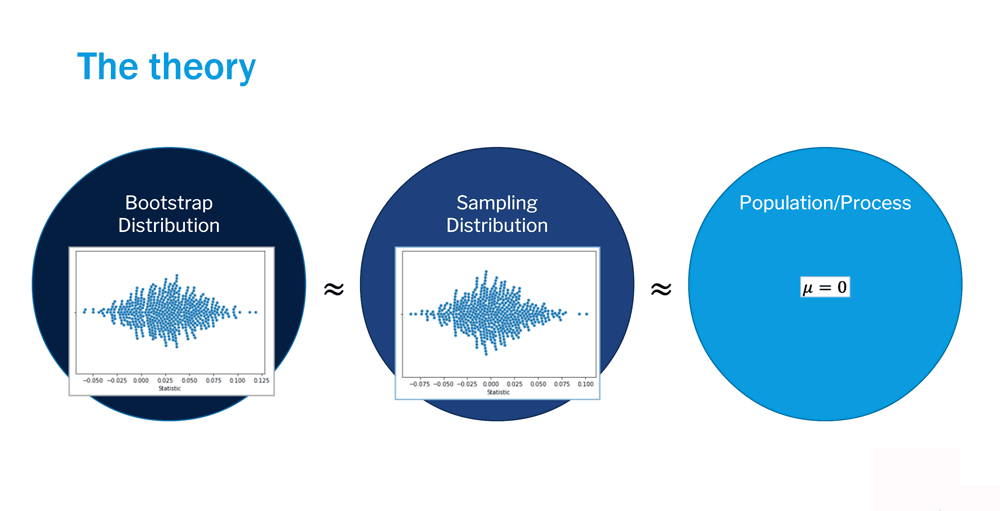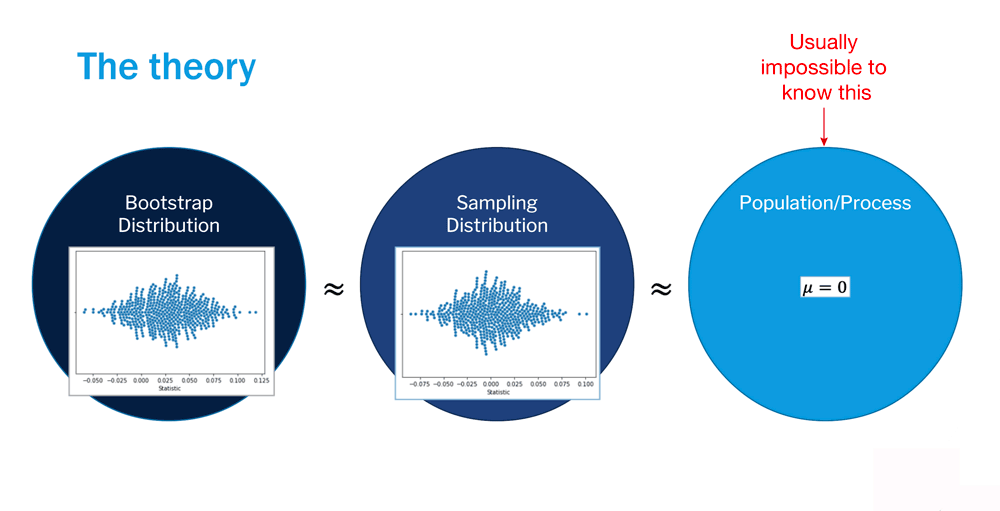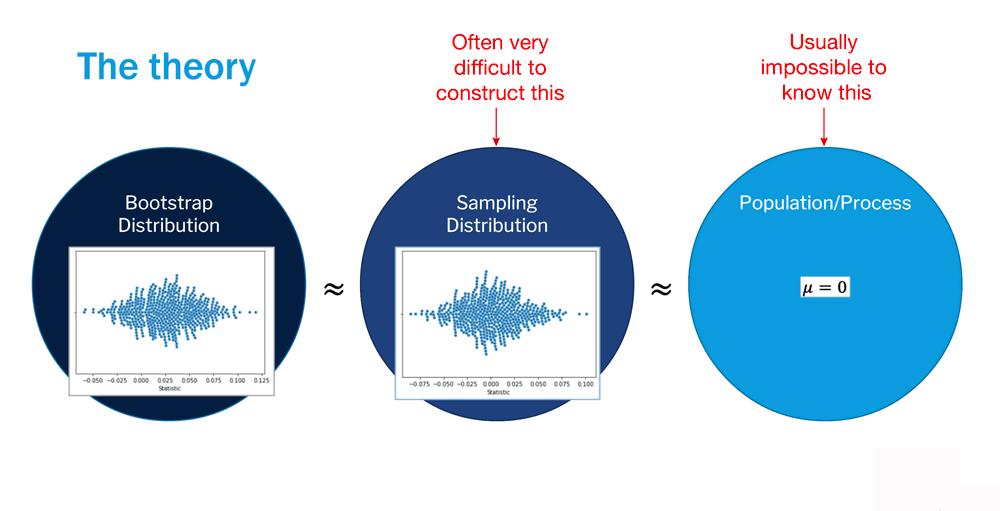
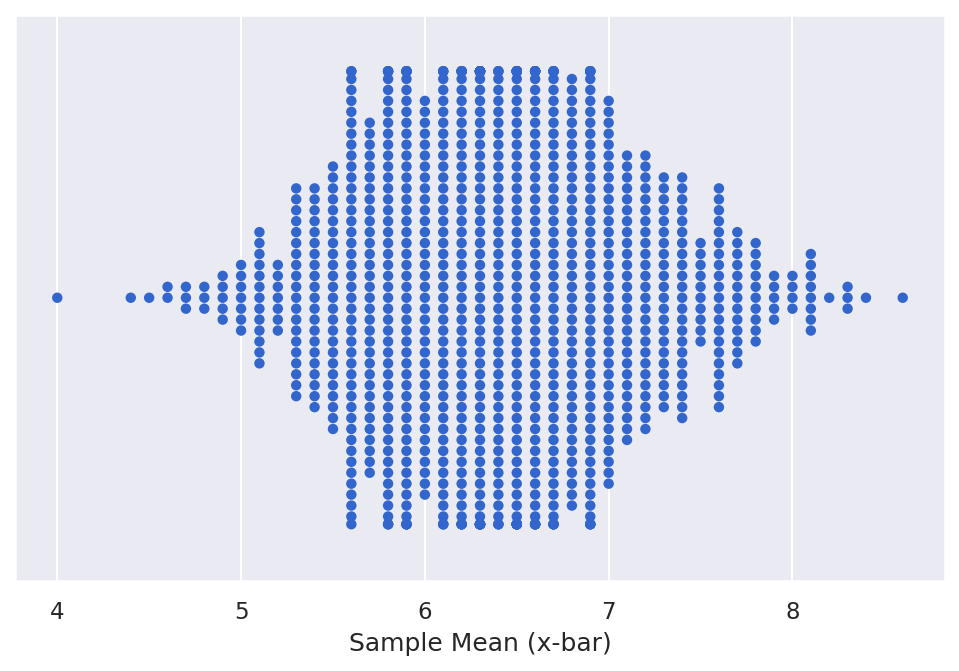
 Watch It: Video - Introduction to Bootstrapping (11:29 minutes)
Watch It: Video - Introduction to Bootstrapping (11:29 minutes) Try It: Apply Your Coding Skills in Google Colab
Try It: Apply Your Coding Skills in Google Colab Assess It: Check Your Knowledge
Assess It: Check Your Knowledge FAQ
FAQ