Introduction to Linear Regression
 Read It: Introduction to Linear Regression
Read It: Introduction to Linear Regression
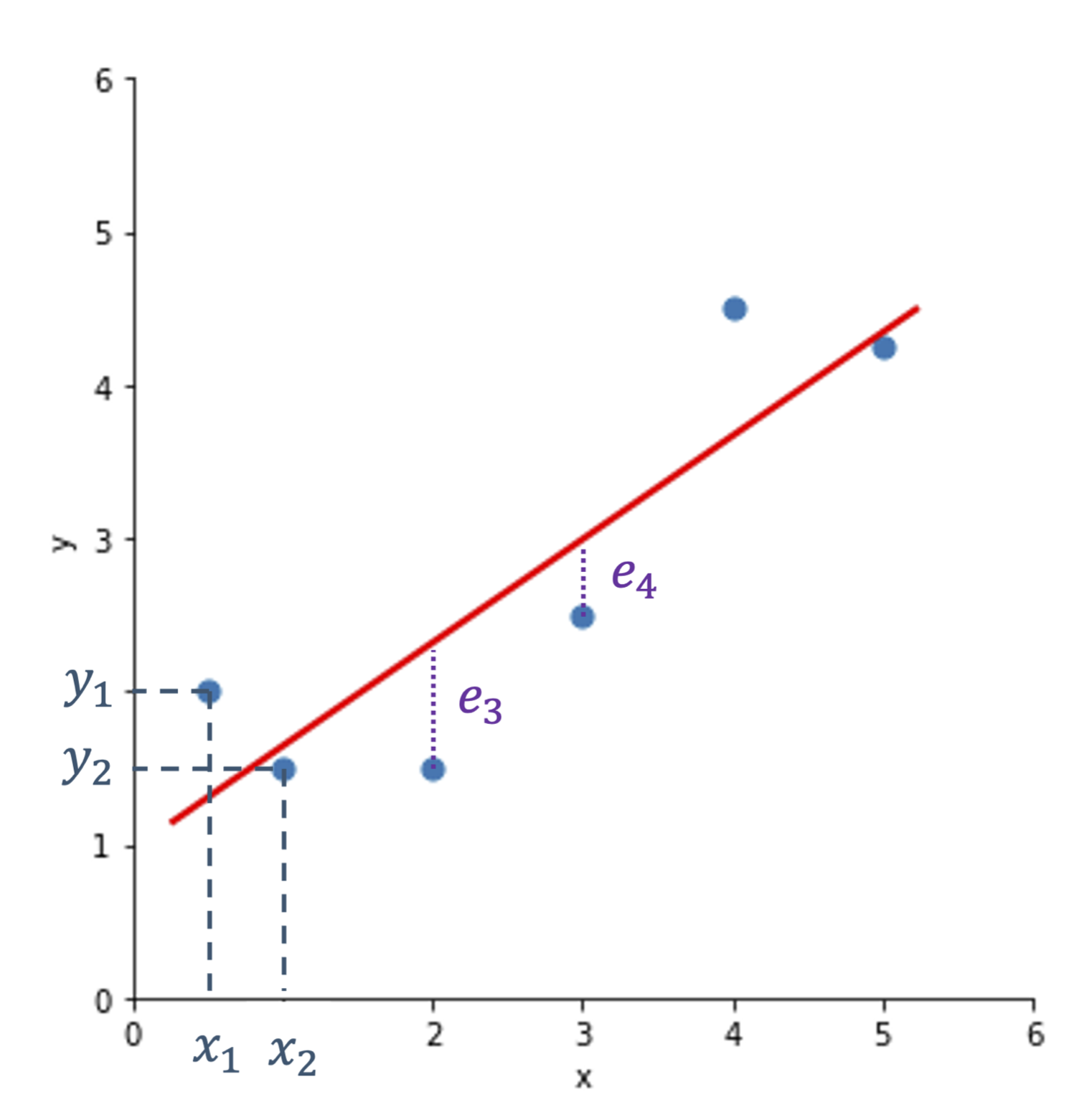
The goal of linear regression is to predict some value y based on the relationship between y and x. In practice, this means we try to find the best fit line to minimize the error. This is shown in the figure below, where we want to find the best line that minimizes the total difference between the data points and the line. The differences are denoted with the letter e. We then define the line based on the slope and intercept, ultimately following the classic equation: , where is the slope and is the intercept.
When working with a sample of data, we usually denote the line as: . For a population, we change the equation to include uppercase letters:
A key aspect of this latter equation is that epsilon is normally distributed (e.g., ). In fact, the normally distributed error is a critical assumption in linear regression models. Additional assumptions include: (a) a linear relationship between x and y, (b) constant variability in the data, and (c) no outliers present. Examples of how each of these conditions might be broken are provided below.


In particular, Figure (a) shows how the first condition (linearity) might be broken. Notice how the pattern is distinctly curved, rather than straight. In Figure (b), the second condition (constant variability) is broken. Here, we see a fan or wedge shape, which indicates that the variance between the y data at x = 20 is much larger than that at x = 10. This means that the variance is not constant, thus breaks one of the conditions for linear regression. Finally, Figure (c) shows the third condition (no outliers) being broken. In particular, there are four likely outliers, which leads to the broken condition. Below, is an example of an ideal example for meeting all three conditions. Notice that the pattern is relatively straight, without increasing variance, and there are no outliers. When conducting linear regression, this is how we want our data to look in an ideal world. Unfortunately, real-world data is rarely this perfect, so we often have to conduct transformations to ensure the model is statistically valid. We will go over these transformations later in the course.
 Assess It: Check Your Knowledge
Assess It: Check Your Knowledge