Two-Way Chi-Square Tests
 Read It: Two Chi-Square Test
Read It: Two Chi-Square Test
So far in this lesson we have focused on one-way chi-square tests. These tests focus on comparing one categorical variable to known proportions. There is, however, another version of the chi-square test known as the two-way test. Two-way chi-square tests compare two categorical variables, rather than one. Additionally, the degrees of freedom are calculated differently: where is the number of rows and is the number of columns. Below, we demonstrate two tables that might be used in chi-square tests. The table on the left shows a single categorical variable, for which we would conduct a one-way chi-square test. Conversely, the table on the right shows a two-way table (e.g., there are categorical variables along the rows and columns), for which we would need to conduct a two-way chi-square test.
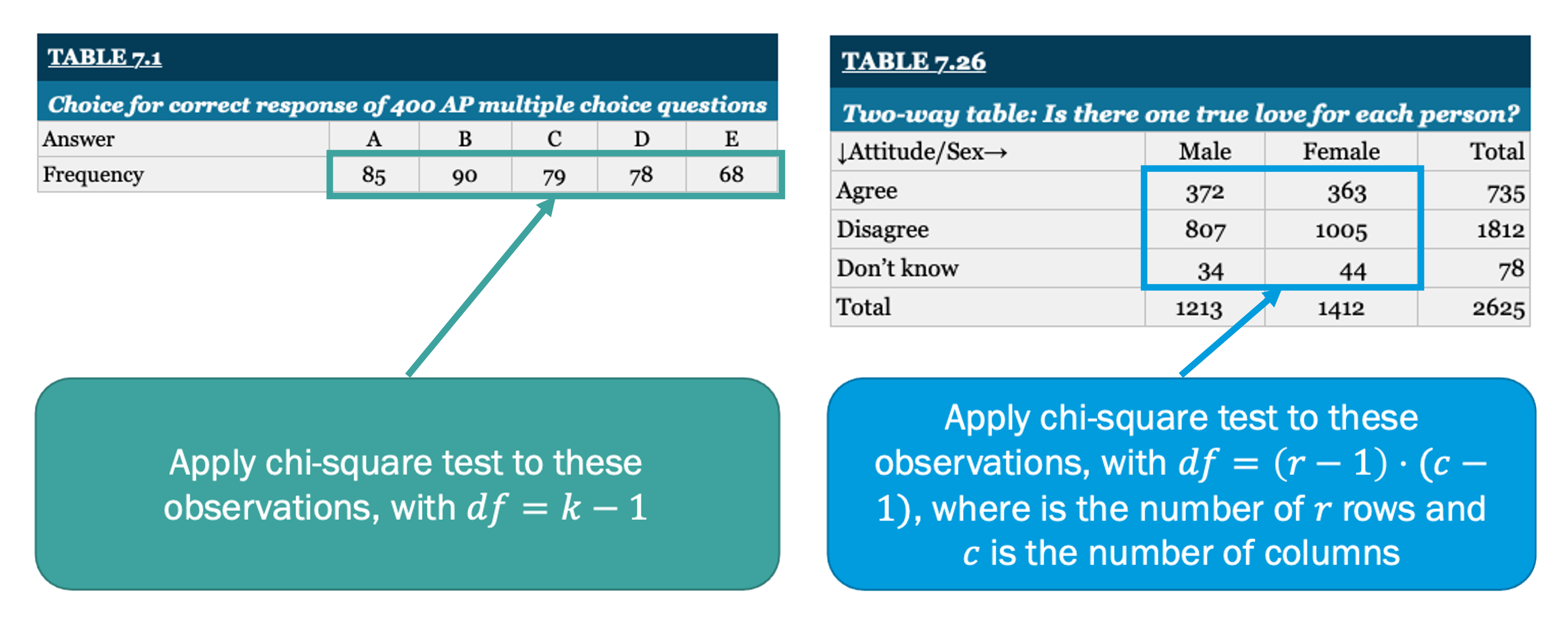
| Table 7.1 | |||||
|---|---|---|---|---|---|
| Choice for correct response of 400 AP multiple choice questions | |||||
| Answer | A | B | C | D | E |
| Frequency | 85 | 90 | 79 | 78 | 68 |
| Table 7.26 | |||
|---|---|---|---|
| Two-way table: Is there one true love for each person? | |||
| Attitude/Sex | Male | Female | Total |
| Agree | 372 | 363 | 735 |
| Disagree | 807 | 1005 | 1812 |
| Don't know | 34 | 44 | 78 |
| Total | 1213 | 1412 | 2625 |
Below, we provide a demonstration of a two-way chi-square test using the card drawing activity from earlier. In particular, we will use the stats.chi2_contingency command from the scipy.stats library. You can read more about this command here(link is external).
 Watch It: Video - Two-Way Test (9:00 minutes)
Watch It: Video - Two-Way Test (9:00 minutes)
 Try It: GOOGLE COLAB
Try It: GOOGLE COLAB
- Click the Google Colab file used in the video here(link is external).
- Go to the Colab file and click "File" then "Save a copy in Drive", this will create a new Colab file that you can edit in your own Google Drive account.
- Once you have it saved in your Drive, use the card drawing simulator linked here(link is external) to create some data and implement a two-way chi-square test:
Note: You must be logged into your PSU Google Workspace in order to access the file.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # draw cards and populated the table with the number of wins and losses by suittable2['Count'] = [0, 0, # diamonds 0, 0, # hearts 0, 0, # clubs 0, 0] # spades# reorganize the table using pd.crosstabtable3 = pd.crosstab(table2['Suit'], table2['Win?'], values = table2['Count'], aggfunc = np.sum, margins = False)# conduct testresults = ...results# print p-valueprint('p-value: ', ...) |
Once you have implemented this code on your own, come back to this page to test your knowledge.
OPTION 2 : DATACAMP
Try It: OPTION 2 DataCamp - Apply Your Coding Skills
Dictionaries are a quick way to create a variable from scratch. However, their functionality is limited, so we will often want to convert those dictionaries into DataFrames. Try to code this conversion in the cell below. Hint: Make sure to import the Pandas library.
 Assess It: Check Your Knowledge
Assess It: Check Your Knowledge